








Last Updated on 2025年3月12日 by カメさん

こんにちは!看護師のカメさん(@49_kame)です。
この記事は6~7分程度で読めます。
今回は統計解析ソフトEZRを使用して実際に分割表の検定(カイ二乗検定)を行う方法を解説します。
分割表の検定は、研究におけるカテゴリカルデータ(名義尺度や順序尺度などの質的データ)の分析に使用される手法です。この手法は、特に2つの変数間の関係性を調べる際に用いられ、それぞれの変数がどのように関連しているか、または独立しているかを統計的に評価します。
分割表の検定は、その直感的な解釈と計算の単純さから、看護研究でも広く利用されています。この手法を用いることで、複雑なデータセットからも明確で理解しやすい結果を導き出すことが可能になります。
今回は、統計手法の基礎的な内容を解説した後で、デモデータを使用して実際に分割表の検定を行う手順を、初学者でも理解できるように丁寧に解説していくのでよろしくお願いします。
この記事を通じて、統計解析の基本を学び、自身の研究や実務に活かす一助となれば幸いです。
このブログでは統計解析ソフトしてEZRを使用しています。EZRは無料かつ精度も高い統計解析ソフトであるためおすすめです。EZRの概要とインストール方法については【EZRの概要とインストール方法】看護研究を変える!EZRで効率的な統計解析を参照してください。
はじめに
まずは分割表の検定を行うための基礎知識から解説するよ
分割表の検定の概要を知りたい方は【分割表の検定(カイ二乗検定):概要編】看護研究の疑問を解決「質的変数を分析しよう」を参照してください。
分割表の検定とは?
分割表の検定とは、カテゴリカルデータ(質的変数)の関係性を分析する方法です。カテゴリカルデータ(質的変数)とは男性や女性など、分類のみに意味があるデータなどです。
長さや重さとは異なり、それ自体では計算できないデータのことだよ
分割表の検定では、分割表というものを使用します。分割表とは、下記の図のように行と列にそれぞれ変数を置いて、変数毎の人数を集計したものです。分割表はクロス集計表とも呼ばれます。
下記の図では行に性別、列に疾患名を置いて、変数毎の人数を集計しています。セルの中が、それぞれの条件に当てはまる人数になっています。
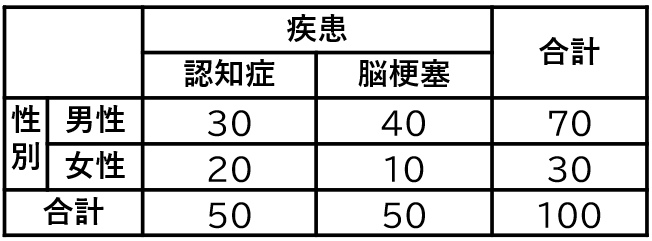
分割表の検定では、集計した人数を分析することにより、変数同士の関連を調べます。行に介入や要因、列に結果を記載するのが一般的です。上記の表だと、性別が要因となり、疾患の発生に影響するかどうかを調査するということです。
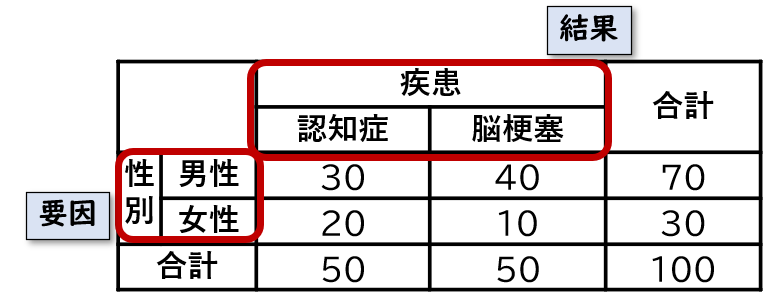
上記の表を見ると、性別により疾患の発生人数が異なるため、なんだか性別と疾患に関連がありそうな印象があります。これを統計的に確認するのが分割表の検定です。
今回は2×2の表を例として示したけど、例えば要因を3つに増やした2×3の表などでも分割表の検定を行うことができるよ。
分割表の検定の基本手順
下記が分割表の検定の基本手順です。
分割表の検定では以下の2つのポイントで検定方法が異なります。
- ➀症例数
- ②期待値
症例数とは、研究でデータを収集した対象者数のことです。また期待値とは、収集したデータを均等にセルに配置した値のことです。
期待値については後程詳しく解説します。先に検定の基本手順について解説するよ。
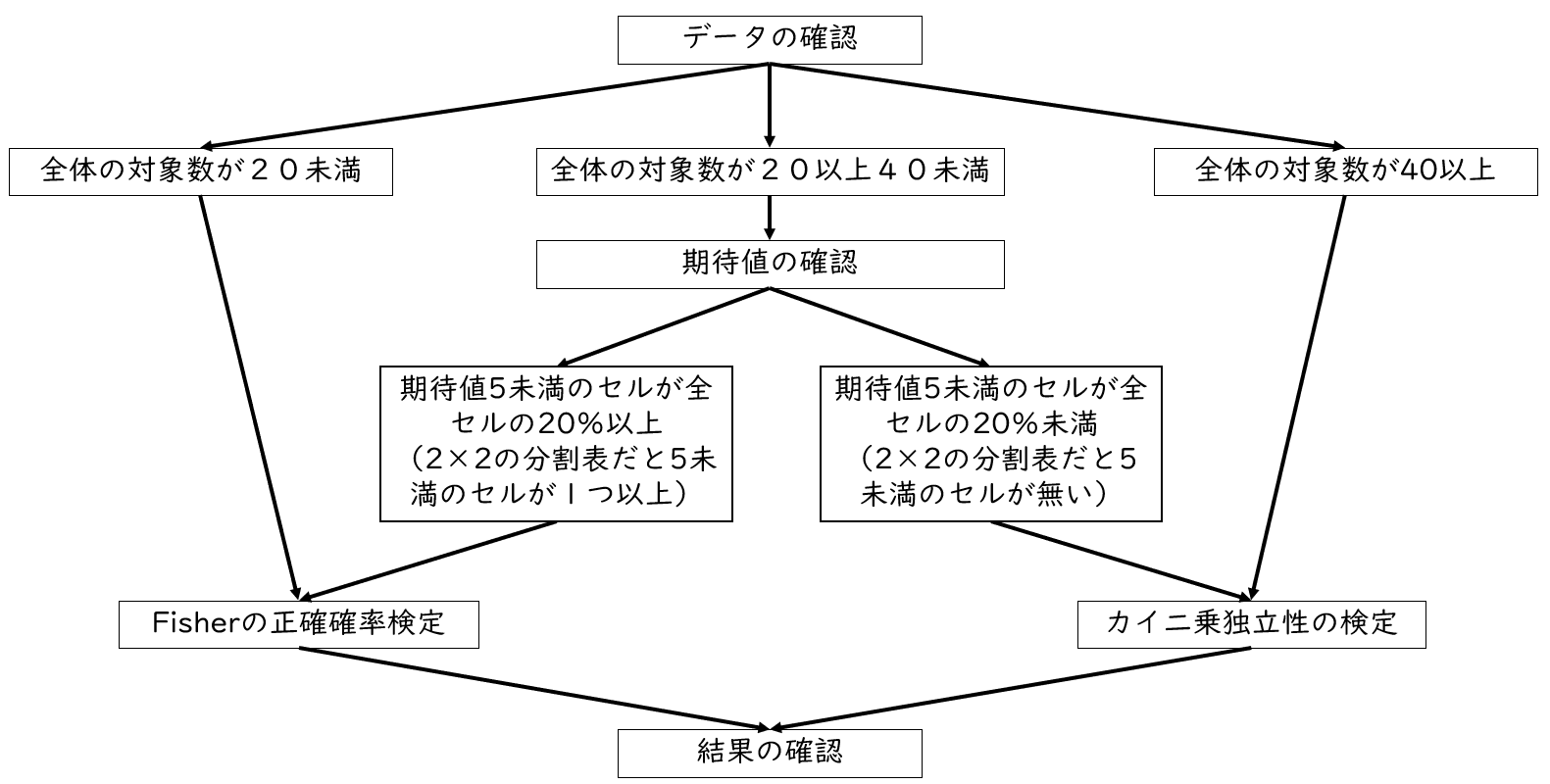
まずはデータを確認し症例数を確認します。全体の症例数が20未満であれば、Fisher(フィッシャー)の正確確率検定を使用します。また全体の症例数が40以上の場合は、カイ二乗独立性の検定を使用します。
症例者数が20以上40未満の時は期待値を確認します。期待値が5未満のセルが全セルの20%以上(つまり2×2の分割表だと5未満のセルが1つ以上)の場合はFisher(フィッシャー)の正確確率検定を使用し、期待値5未満のセルが全セルの20%未満(つまり2×2の分割表だと5未満のセルが無い)場合はカイ二乗独立性の検定を使用します。
期待値とは?
期待値とは、変数同士にまったく関連がないと仮定したときに、列合計と行合計の割合を加味して、各セルに人数を均等に配置した値です。
つまり、行と列の変数同士に何も関係がない状況の各セルの数字が期待値だよ。
期待値は、期待値を算出したいセルの列合計×行合計÷総合計で算出されます。例えば、下記の図の例だと、列合計50、行合計50、総合計100なので、期待値は セルの列合計(50)×行合計(50)÷総合計(100)= 25になります。
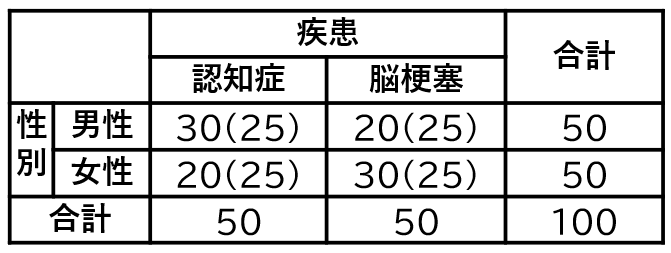
上記の場合、行合計と列合計が同じなので、4つのセルの期待値は全て25になります。つまり、行と列の変数同士に何も関係ない状況で、セルに均等に数字を割り付けると()の中の値である期待値は25人になるということです。
結果の捉え方は「期待値は25人だけれども、実際に測定された人数は25人ではないので、変数同士に関係があるかもしれない」と考えます。
期待値5未満のセルとは?
それでは、先ほどの基本手順に記載の「期待値が5未満のセル」とはどのような意味かについて解説していきます。「期待値5未満のセル」がある状況とは下記の図のような場合です。()の中は上記と同様に期待値が記載されています。
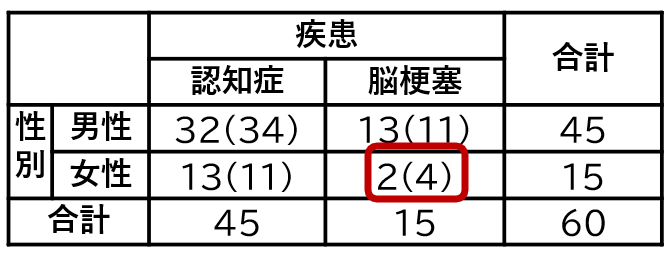
上記の図から分かる通り、他のセルと比較して1つのセルに当てはまる人数が少ない状況のことです。今回の場合であれば、収集したデータのうち脳梗塞の女性が2名であり、かなり少ない状況です。
このような「期待値5未満のセル」が全セルの20%以上(つまり2×2の分割表だと5未満のセルが1つ以上)の場合には、Fisher(フィッシャー)の正確確率検定を使用します。また、「期待値5未満のセル」が全セルの20%未満(2×2の分割表だと5未満のセルが無い)場合はカイ二乗独立性の検定を使用します。
とはいえ、実際に期待値を確認するのは大変です。そのため期待値は確認せず、基本的にFisherの正確確率検定を使用して、対象数100人以上のような極端に大きなサンプルの場合にカイ二乗独立性の検定を行うという考え方もあります。
EZRで行う分割表の検定の検定手順
ここからはEZRを使用して分割表の検定を行う方法について解説します。
今回使用するデモデータ
今回は下記のデモデータ(一部抜粋)を使用します。
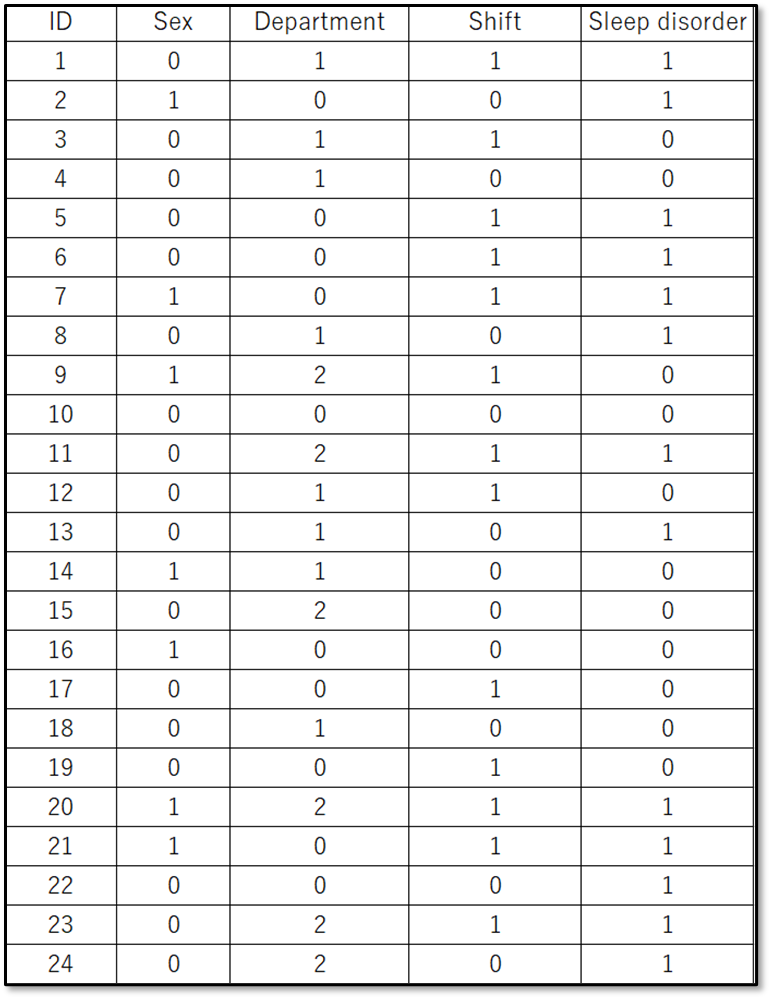
表示しているのは、デモデータの一部です。デモデータは下記からダウンロードできるので使ってみてください。
ランダム関数で作成しているため、今回の結果とズレが出るかもしれませんが、ご了承ください。
こちらのデモデータを読み込んだ後の段階から解説します。データの読み込み方法については【統計解析ソフトにデータを入力】看護研究初めの一歩:EZRにデータセットを入力しよう!を参照してください。
ちなみに、上記のデモデータでは質的変数をダミー変数に変換しています。今回は、質的変数同士の関係性を確認する分析なので、全てダミー変数に変換します。なので性別と部署、シフト、睡眠障害の有無について下記の図のようにダミー変数に変換しています。
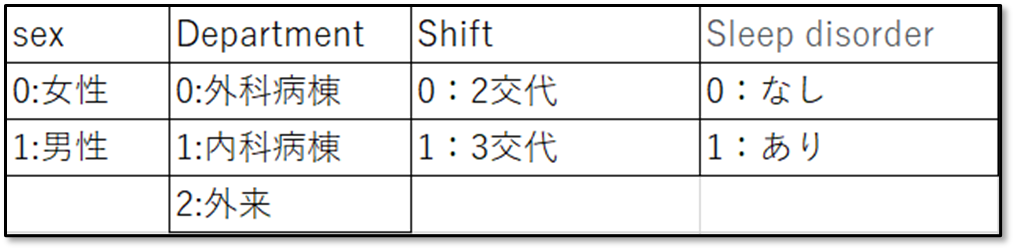
ダミー変数について詳しく知りたい人は「【ダミー変数とは?】看護研究の疑問を解決「多変量解析で質的変数を使用する方法を解説」を確認してね。
検定手順➀:データを確認する
それでは検定の手順を確認していきましょう。まずはデータの確認です。データによって分析方法が異なるので確認しましょう。

おさらいですが重要なポイントは症例数と期待値です。
まずはデータを確認して、症例数を確認します。全体の対象数が20未満と低ければ、フィッシャーの正確確率検定です。また全体の対象数が40以上の場合は、カイ二乗独立性の検定です。
やっかいなのが、対象者数20以上、40未満の時です。この時は、先ほどの期待値を確認します。期待値5未満のセルが全セルの20%以上(つまり2×2の分割表だと5未満のセルが1つ以上)の場合はフィッシャーの正確確率検定で、期待値5未満のセルが全セルの20%未満(つまり2×2の分割表だと5未満のセルが無い)場合はカイ二乗独立性の検定を選択します。
上記でもお伝えした通り、基本的にフィッシャーの正確確率検定を使用して、対象数100人以上のような極端に大きなサンプルの場合にカイ二乗独立性の検定を行うという考え方もあります。
カイ二乗検定は100以下のサンプルだと不適切になることが多いためです。一つの考え方として覚えておきましょう。
検定手順②:分割表の検定を行う
分析方法の選択について色々と説明しましたが、EZRであればフィッシャーの正確確率検定もカイ二乗検定も同時に算出できるので、同時に確認していきましょう。

まずは、EZRの操作画面から、「統計解析」→「名義変数の解析」→「分割表の作成と群間の比較(Fisherの正確検定)」を選択します。
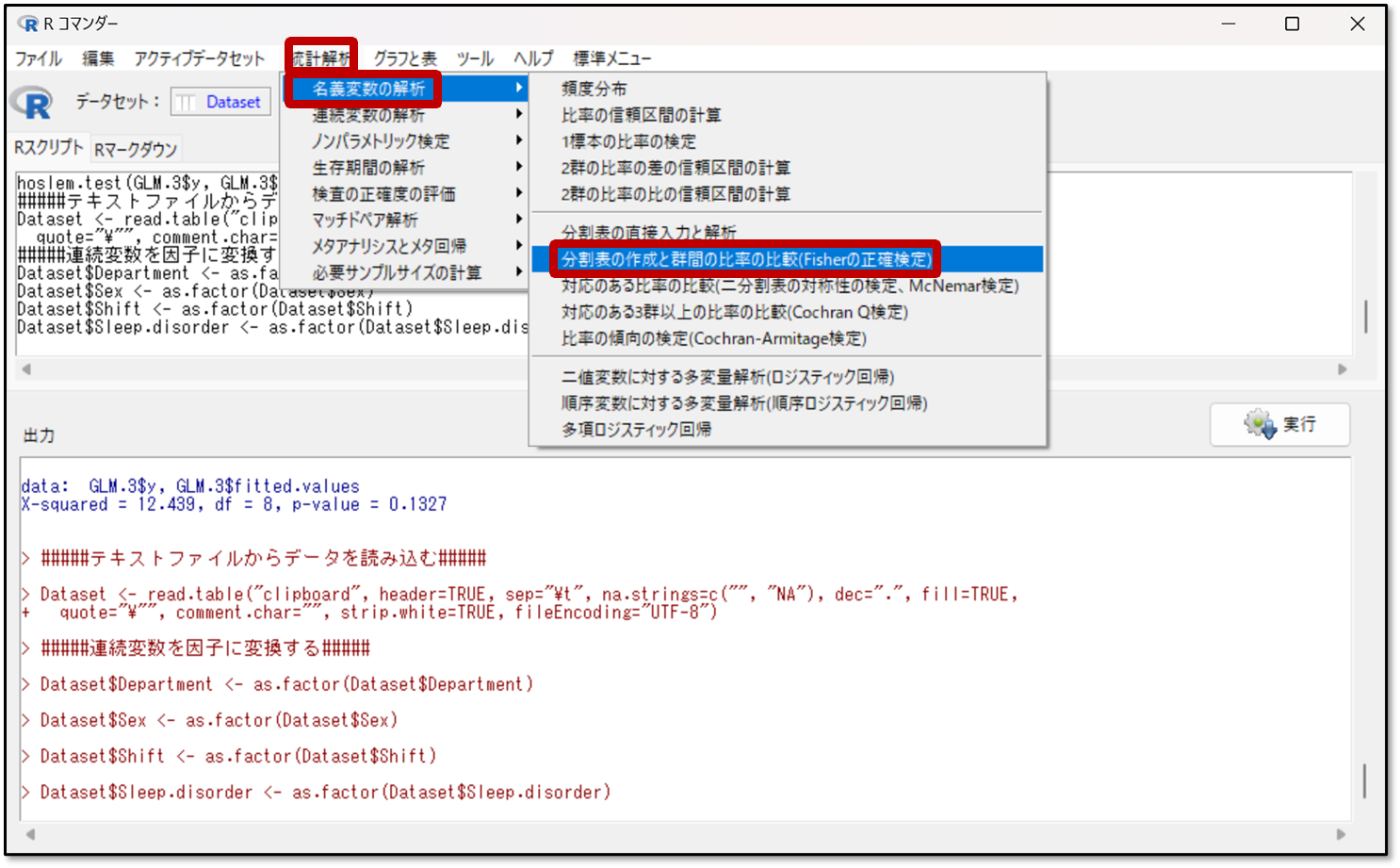
下記の操作画面で、行の変数と列の変数を選択します。行が要因で、列が結果です。要因(行)は複数選択でき、結果(列)は、1つだけ変数を選択します。
上記で使った分割表の例で、要因と結果の位置関係を見ると、下記の図のような感じです。
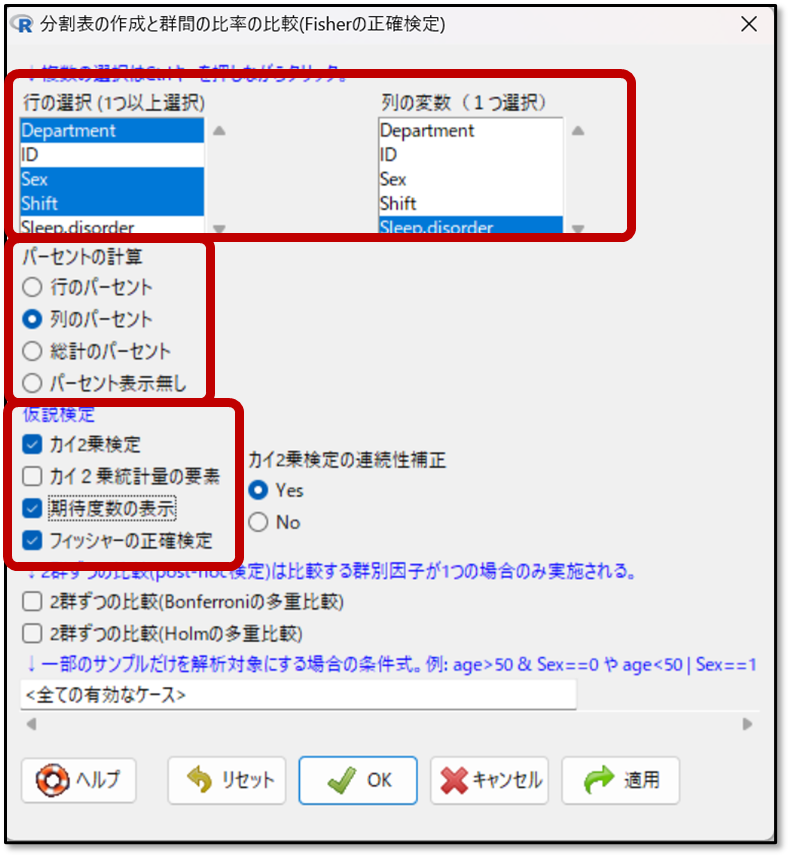
今回は、睡眠障害の有無(結果)について、部署や性別、シフトの違い(要因)が影響するかを確認するので、行(要因)に部署と性別とシフトを、列(結果)に睡眠障害の有無を選択します。
パーセントの計算は「列のパーセント」を選択しましょう。「列のパーセント」を選択することで、行(要因)の変数それぞれが、列(結果)の変数でどのくらいの割合なのかが算出されます。
仮説検定については、カイ二乗検定とフィッシャーの正確検定のどちらもチェックを入れておきましょう。また、全体の対象が20以上、40未満の場合は、期待値の確認も必要になるので、期待度数の表示にもチェックを入れておきましょう。
期待値と期待度数は同じものだよ。
検定手順③:検定の結果を確認する
結果の確認➀:分割表を確認する
EZRの分割表の検定の出力結果には分割表も算出されるので、まずは分割表の結果を確認しましょう。下記のような分割表が出力されます。
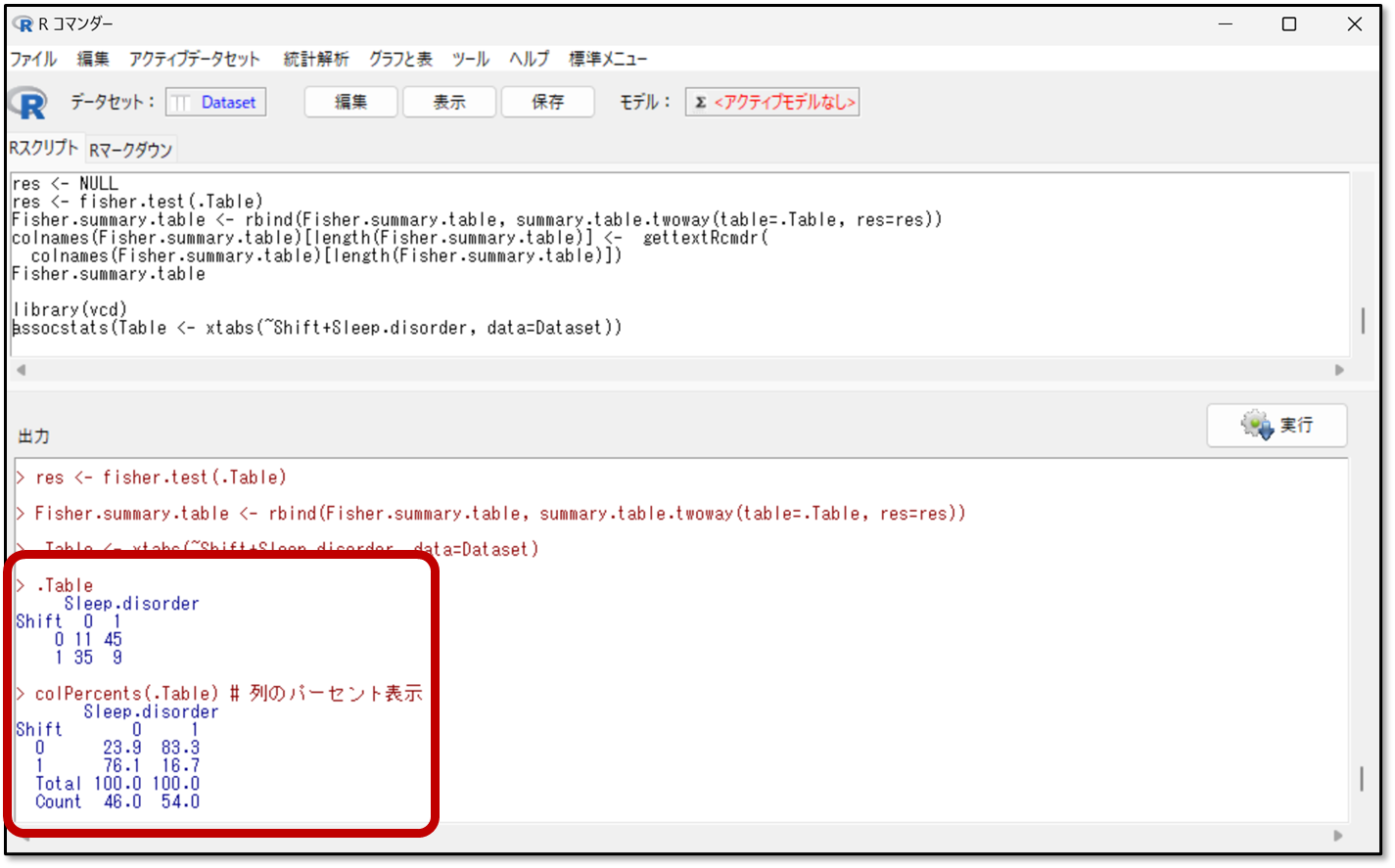
上記の結果の図は、今回の結果のうち、シフト(Shift)と、睡眠障害(Sleep disorder)の関係についての分割表です。2交代と3交代の違いと、睡眠障害の有無なので、2×2の分割表となっています。
ダミー変数に変換前の質的変数が下記の表だよ。
上記の結果の図の「>.Table」には、各変数の実測値が算出されていて、「>colPercents(.Table)」には列のパーセントが表示されています。
線が書いてある表形式の分割表じゃないため少し見づらいと思うので、上の結果の図を表形式にまとめました。
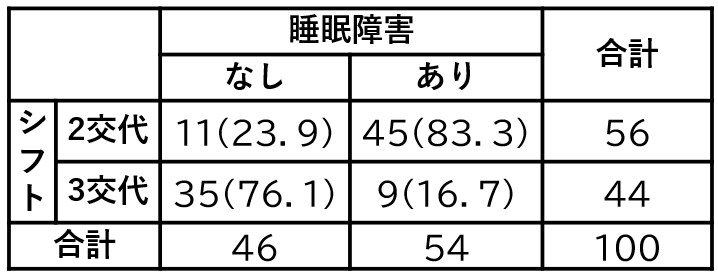
検定結果はまだ確認してないけど、この分割表を見るだけで、なんだか差がありそうな印象があるね。
今回は対象者数が40以上のデモデータを使用していますが、検定手順の解説のため、「対象者数20以上、40未満」の場合について考えてみます。もし今回の対象者数が20以上、40未満であったとしたら、期待値を確認して解析方法を確認する必要があります。
おさらいですが、期待値5未満のセルが全セルの20%以上(つまり2×2の分割表だと5未満のセルが1つ以上)の場合はフィッシャーの正確確率検定で、期待値5未満のセルが全セルの20%未満(つまり2×2の分割表だと5未満のセルが無い)場合はカイ二乗独立性の検定を選択します。

それでは、今回算出された期待値をみてみましょう。下記の結果の図がシフトと睡眠障害の分割表の期待度数(期待値)です。先ほどの操作画面で期待度数の表示を選択すると、この結果が表示されます。
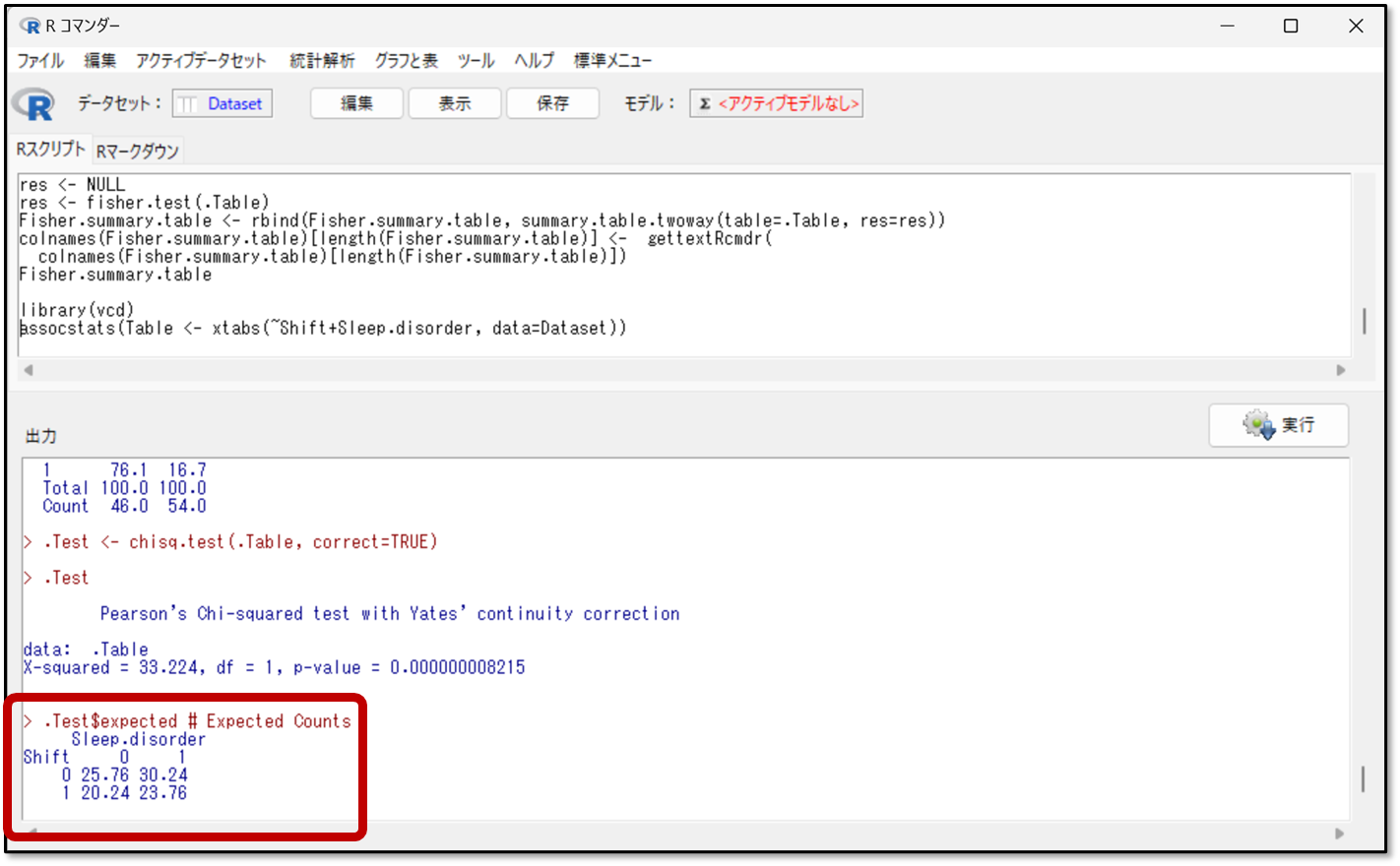
先ほどと同様に、今回の結果の図も表の形式に変換してみました。
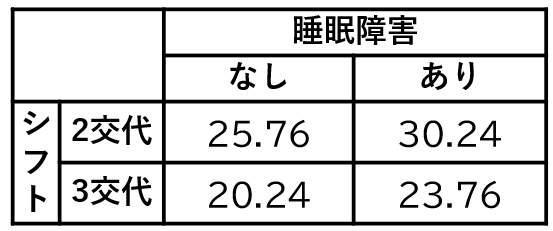
今回は、期待値5未満のセルはなしという結果でした。つまり、もし今回の対象者数が20以上40未満であった場合は、カイ二乗独立性の検定を選択するということです。
ちなみに期待値は、対象者数が少なくて偏りのあるセルで、5未満になるよ。だから今回の結果では、対象者数が特別に偏っているセルがないということも分かるよ。
結果の確認②:有意な関連の有無、関連の強さを確認する
分割表を確認した後は、各変数間の関連について確認します。変数間の関連について確認する際のポイントは以下の2つです。
- 変数間は有意に関連があるのか
- 変数間の関連の強さはどうか
上記2つのポイントで結果を確認するフローが下記の図になります。
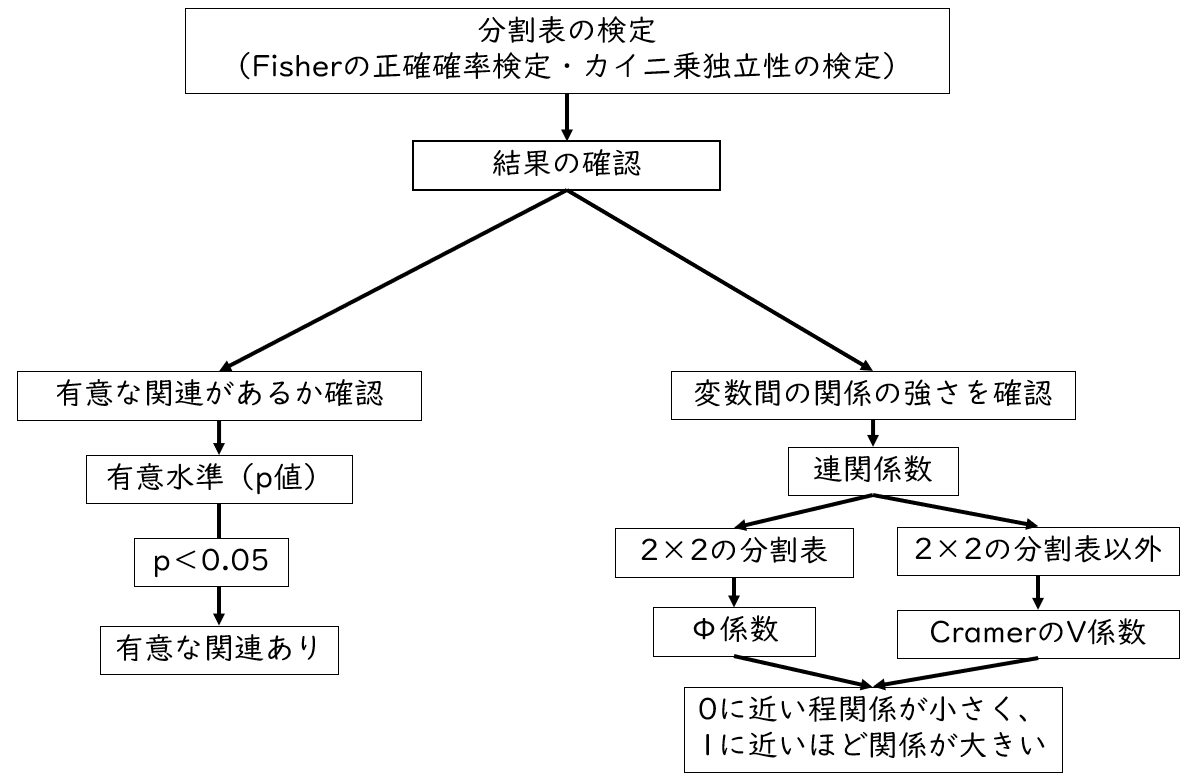
まずは変数間に有意な関連があるかを確認します。検定結果にはp値が算出されるので、p値が0.05未満であれば、有意な関連があると判断します。
次に変数間の関係の強さを確認します。関係の強さは連関係数を確認します。連関係数にも種類があり、例えば2×2の分割表であれば、φ(ファイ)係数を確認します。2×2以上の分割表であればCramer(クラメール)のV係数を確認します。
どちらの連環係数も、0に近い程関係が小さく、1に近いほど関係が大きいと判断します。
変数間に有意な関連があるか(p値の確認)
それでは変数間に有意な関連があるかの判断について詳しく解説します。
変数間に有意な関連があるかどうかは、前述の通りp値(有意水準)から判断します。統計ソフトで分割表の検定を行うと、p値(有意水準)が算出されます。pの値が、0.05未満(p<0.05)であれば、帰無仮説が棄却されて、「変数間に有意な関連がある」と判断することができます
分割表の検定の仮説は、帰無仮説が「2つの変数は独立である」、対立仮説が「2つの変数は独立ではない」となっているよ。帰無仮説や対立仮説について詳しく知りたい人は【p値とは?】有意差の意味を理解しよう!を参照してください。
今回のデモデータを使用した分割表の検定の結果を見ていきます。今回は、フィッシャーの正確確率検定も、カイ二乗検定もどちらも算出される設定としたので、どちらも見ていきます。
まずはフィッシャーの正確確率検定の結果で、有意な関連があるかどうかを確認しましょう。下記がEZRの算出結果です。
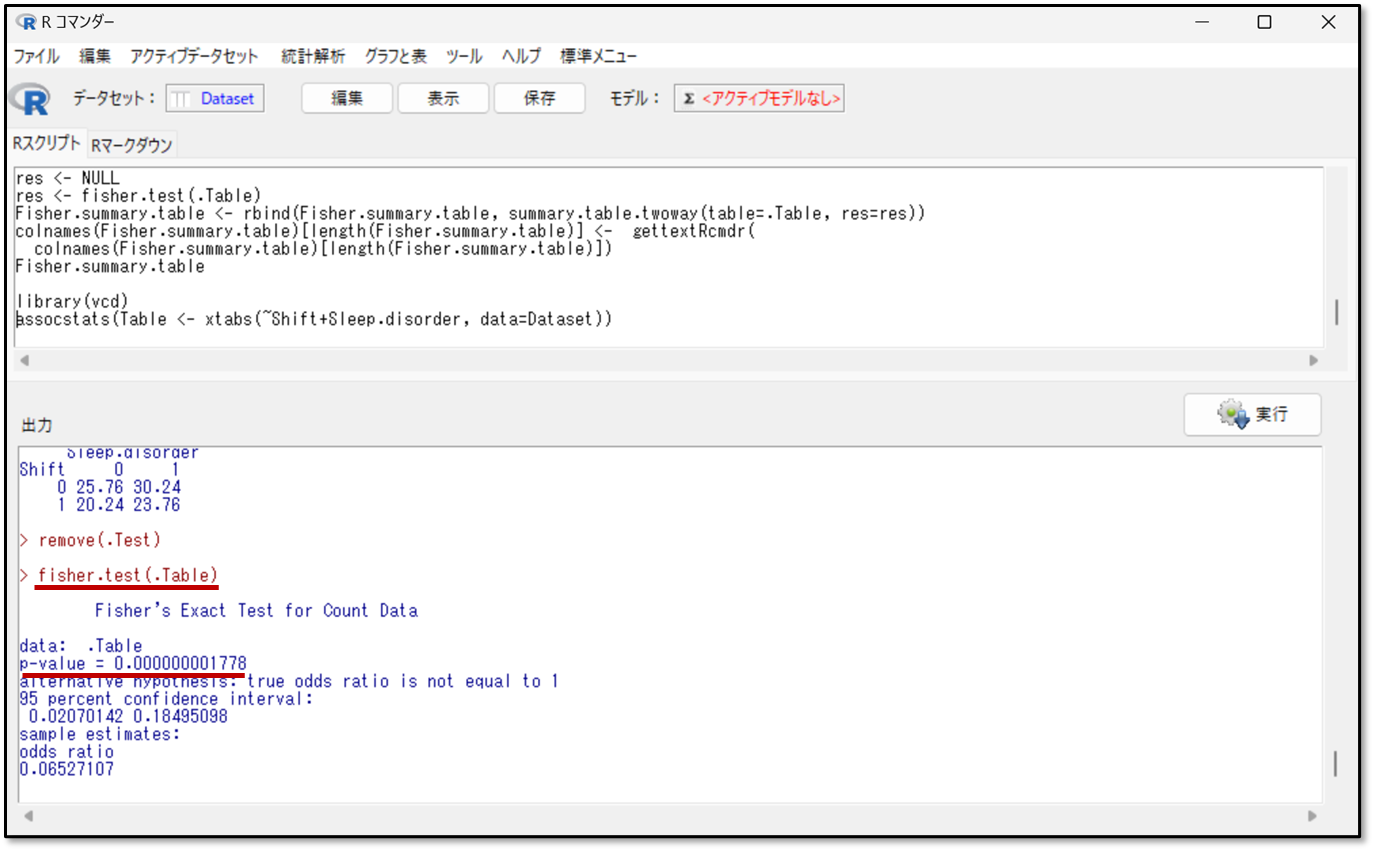
出力結果の見方を解説します。fisher.testつまりフィッシャーの正確確率検定です。p-value(pバリュー)を確認します。pバリューとは、p値のことです。pバリューが0.05未満であれば、有意な関連があると判断します。
今回は例として、先ほど同様にシフトの違いと、睡眠障害の有無についての結果を確認します。pバリューが0.00000000000178 、つまりp<0.05です。なので、有意に関連がありそうです。
次にカイ二乗検定の結果を見ていきます。下記がEZRで出力された検定結果が下記の図です。
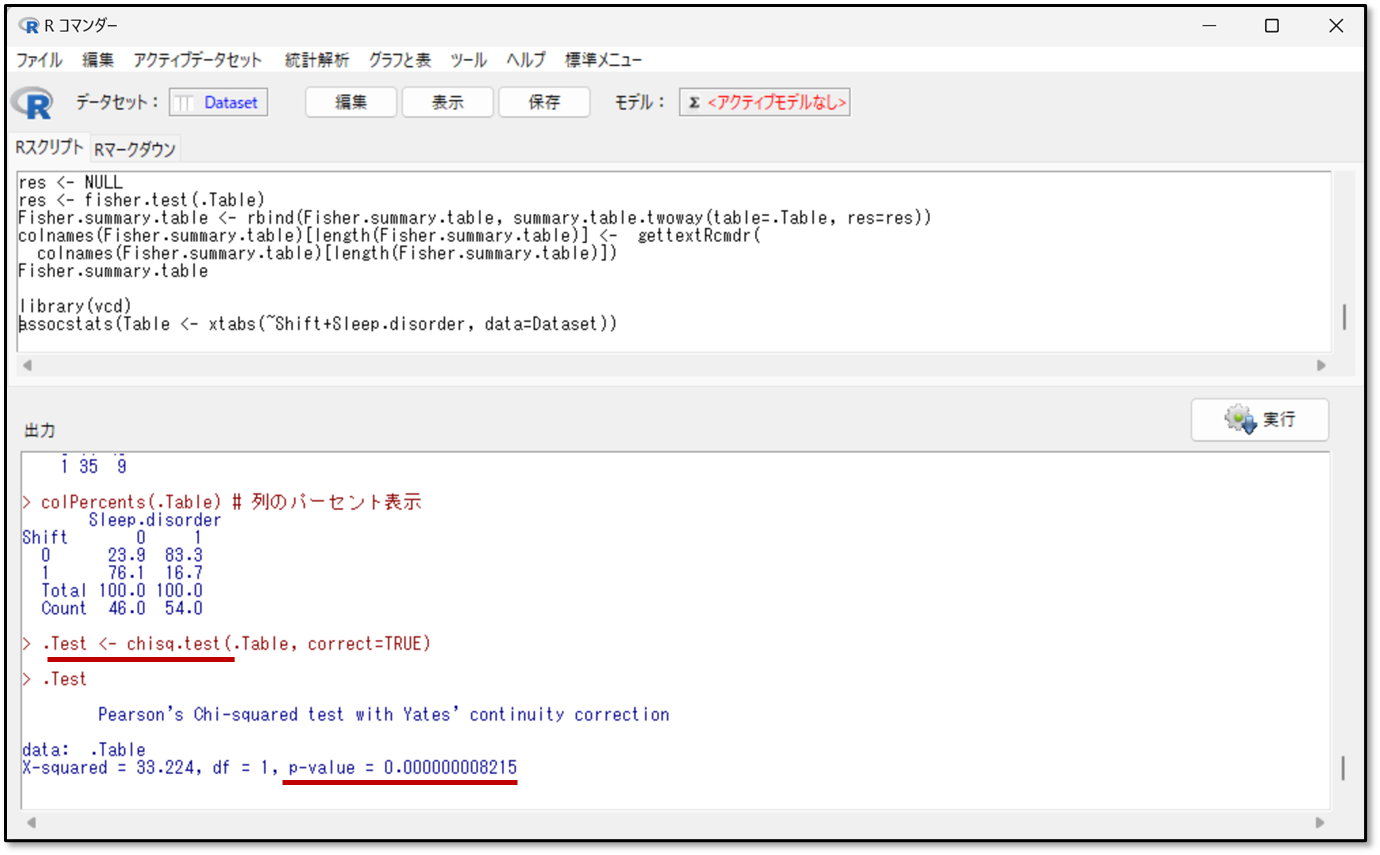
出力結果の見方を解説します。chisq.testが、カイ二乗検定のことです。カイ二乗検定は英語でchi-square testなので、それが省略されて出力結果に表示されています。フィッシャーの正確確率検定と同様に、p-value(pバリュー)つまりp値を確認します。pバリューが0.05未満(p<0.05)であれば、有意な関連があると判断します。
カイ二乗検定についても、上記同様にシフトの違いと、睡眠障害の有無についての結果を確認します。上記の出力結果ではpバリューが0.000000000008215 なので、p<0.05、つまりこちらも有意に関連があることが分かります。
今回は、フィッシャーの正確確率検定もカイ二乗検定もどちらの結果の見方も確認しましたが、本来であれば、今回は100人以上のサンプルのデータなので、カイ二乗検定の結果のみを確認すればOKです。
変数間の関連の強さ
次に変数間の関連の強さについて解説します。
分析の結果、2つの変数間に有意な関連があると分かったら、次に変数間の関連の強さを確認します。変数間の関連の強さは連関係数で判断します。
この連関係数は分割表の数によって異なります。下記の図の通り、2×2の分割表であれば、φ係数を確認します。また、2×2以上の分割表であればCramer(クラメール)のV係数を確認します
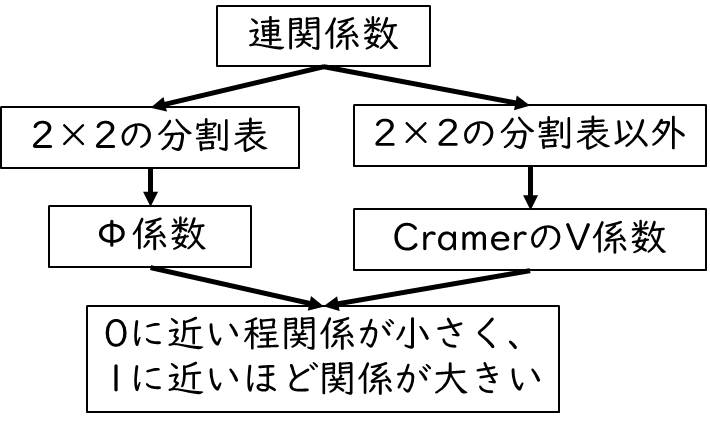
連関係数の判断基準についての考え方は相関係数と同じです。
相関係数について詳しく知りたい人は【相関分析:概要編】看護研究の疑問を解決「2つの変数の関係性を確認しよう」を参照してね。
Φ係数は-1~1の値をとり、クラメールのV係数は0~1の値をとります。連関係数の一般的な判断基準を下記に示します。
例えば、連関係数が0.2未満であれば、関係はほとんどないと判断し、0.7以上であれば、かなり強い関係があると判断します。

上記の判断基準はあくまで目安だから、先行研究や臨床経験を参考に解釈することが大切だよ。
それでは今回のデモデータを使用した出力結果の見方を確認します。連関係数は通常のEZRでは算出することができないため、EZRにパッケージを追加して分析します。
ちなみに、この作業は分割表の検定を解析した後の操作だよ。
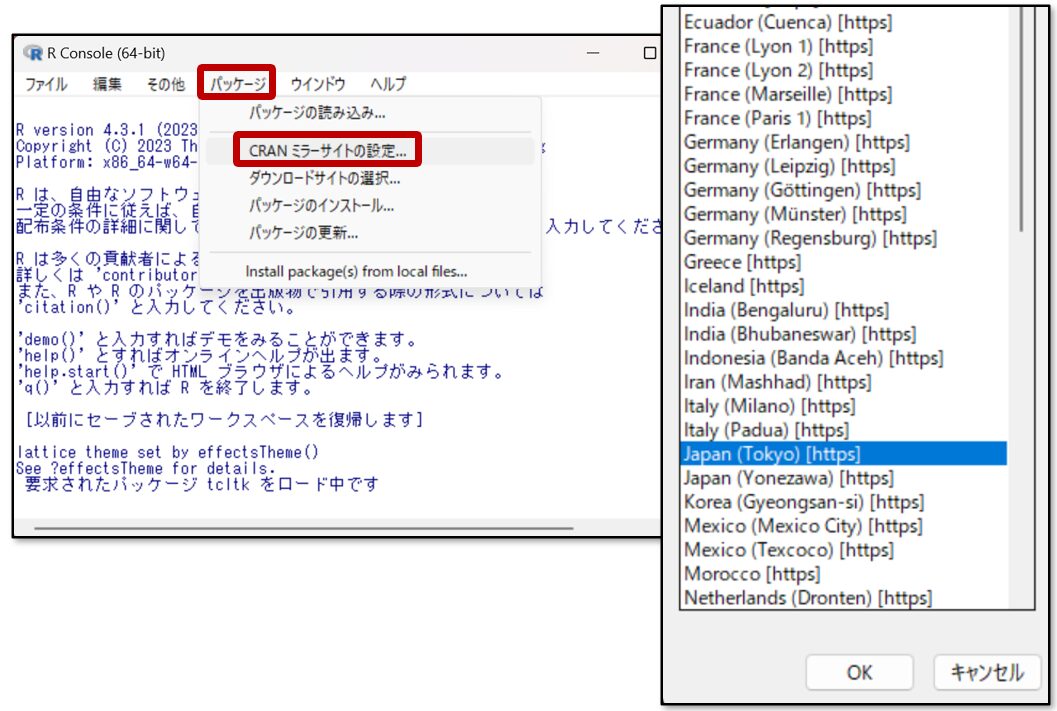
EZRを起動すると、通常の操作画面であるRコマンダーとは別に、下記のようなRコンソールという画面が表示されます。そのRコンソールからパッケージを追加することができます。
まずは「パッケージ」を選択し、次に「ミラーサイトの設定」を選択します。続いて表示される画面の「JAPAN」を選択してOKを押します。
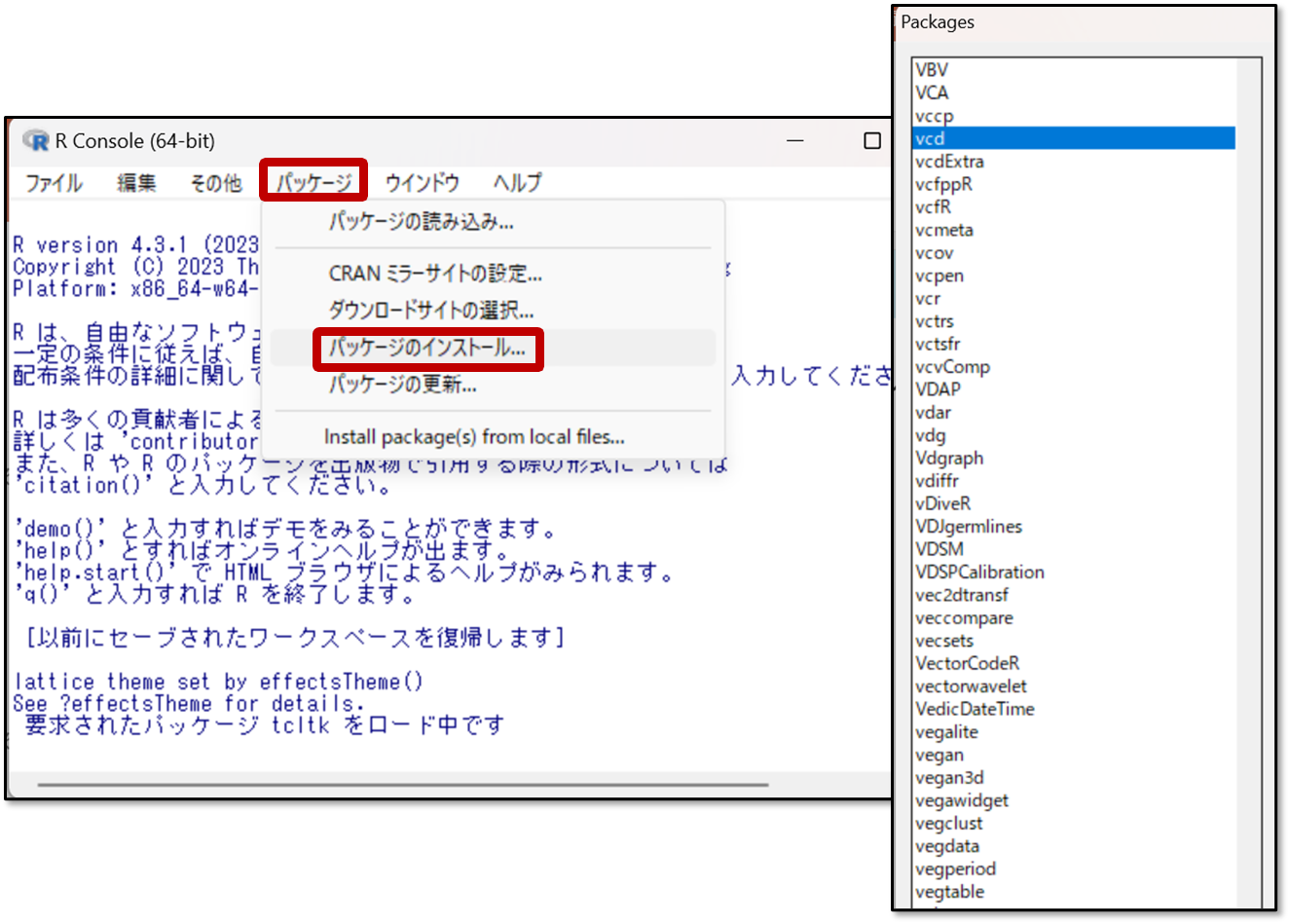
次に「パッケージ」から「パッケージのインストール」を選択し、表示された画面から「vcd」を選択します。これでインストールは完了です。
上記の手順でインストールが完了したら、インストールした「パッケージ」を呼び出して実行します。下記の図にあるRスクリプトに、library(vcd)から始まるコードを入力します。
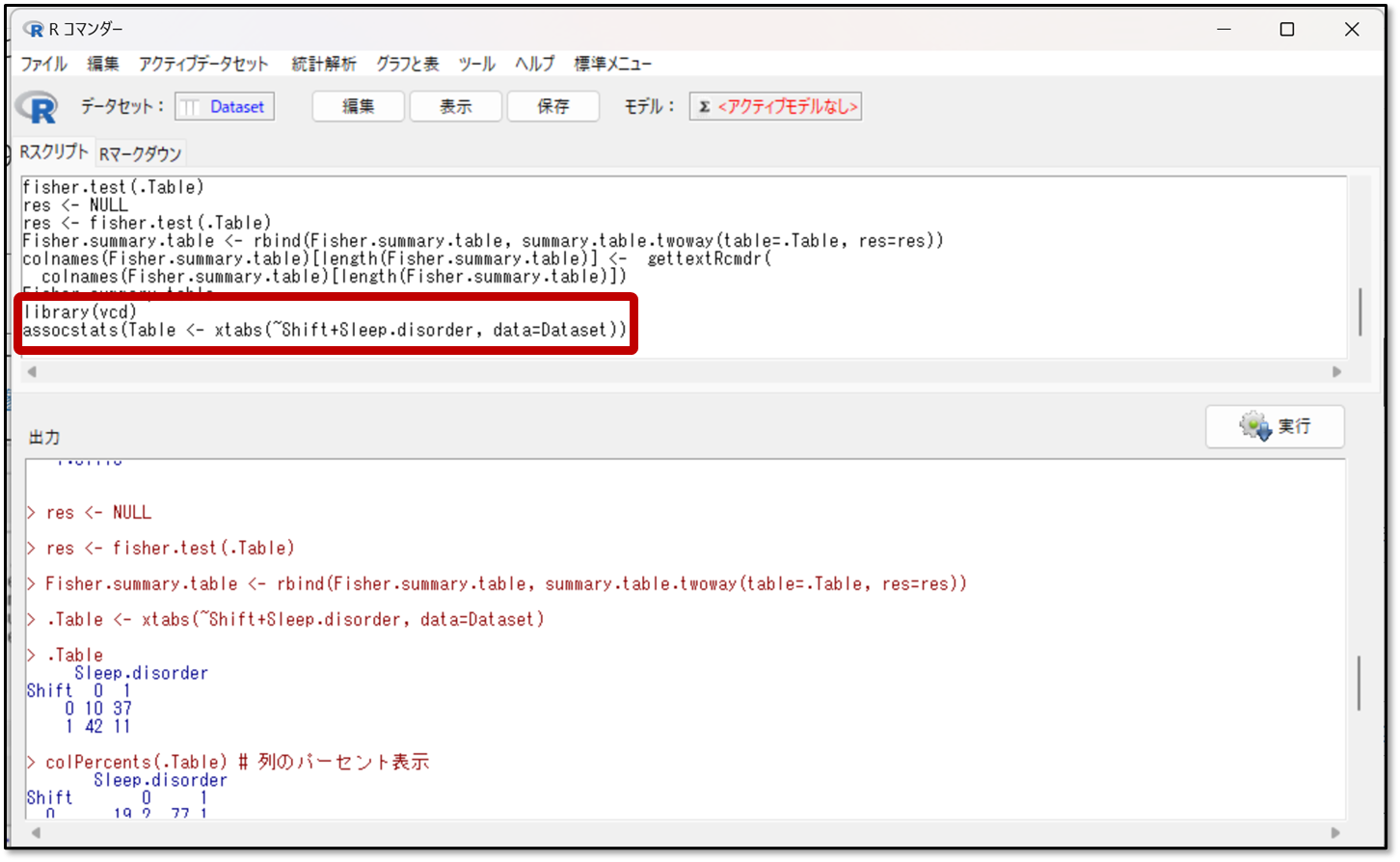
assocstats( )の中に、連関係数を確認したい分割表を、出力結果からコピペして貼り付けます。今回は、先ほどと同様に、シフトと睡眠障害の間での連関係数を確認してみます。下記の出力結果の中で赤枠の部分が、シフトと睡眠障害の分割表を表すので、この部分をコピペします。
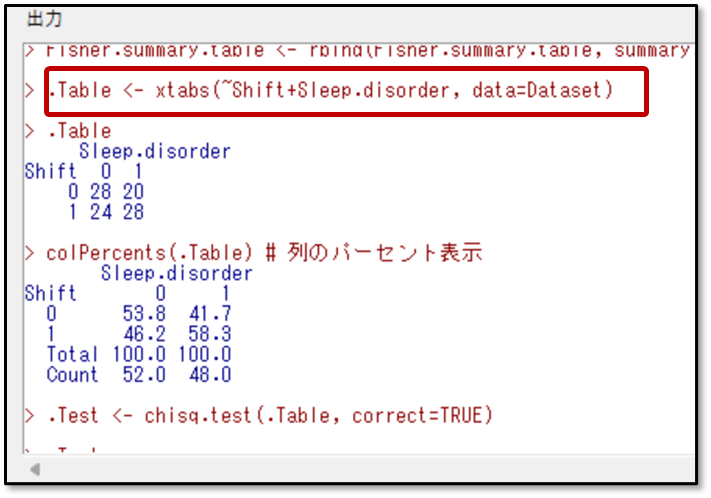
assocstats( )の中に、シフトと睡眠障害の分割表を入力したものが下記になります。
これをRスクリプトに入力したら、下記のようにlibrary(vcd)から始まる部分のみを選択した上で、赤枠の実行ボタンをクリックします。
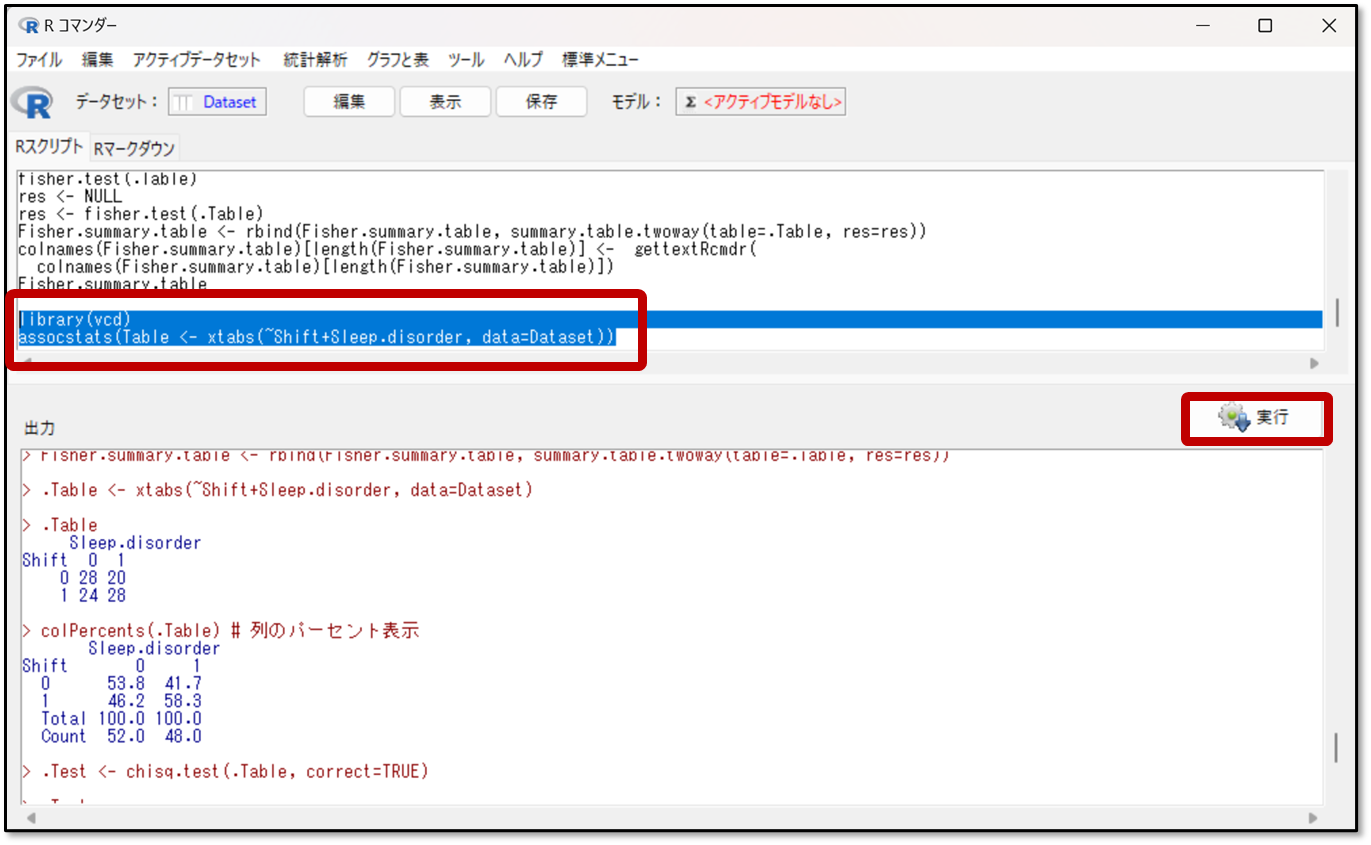
そうすると、連関係数の結果が出力されます。結果の見方を解説します。下記が今回のシフトと睡眠障害についての連関係数の結果です。
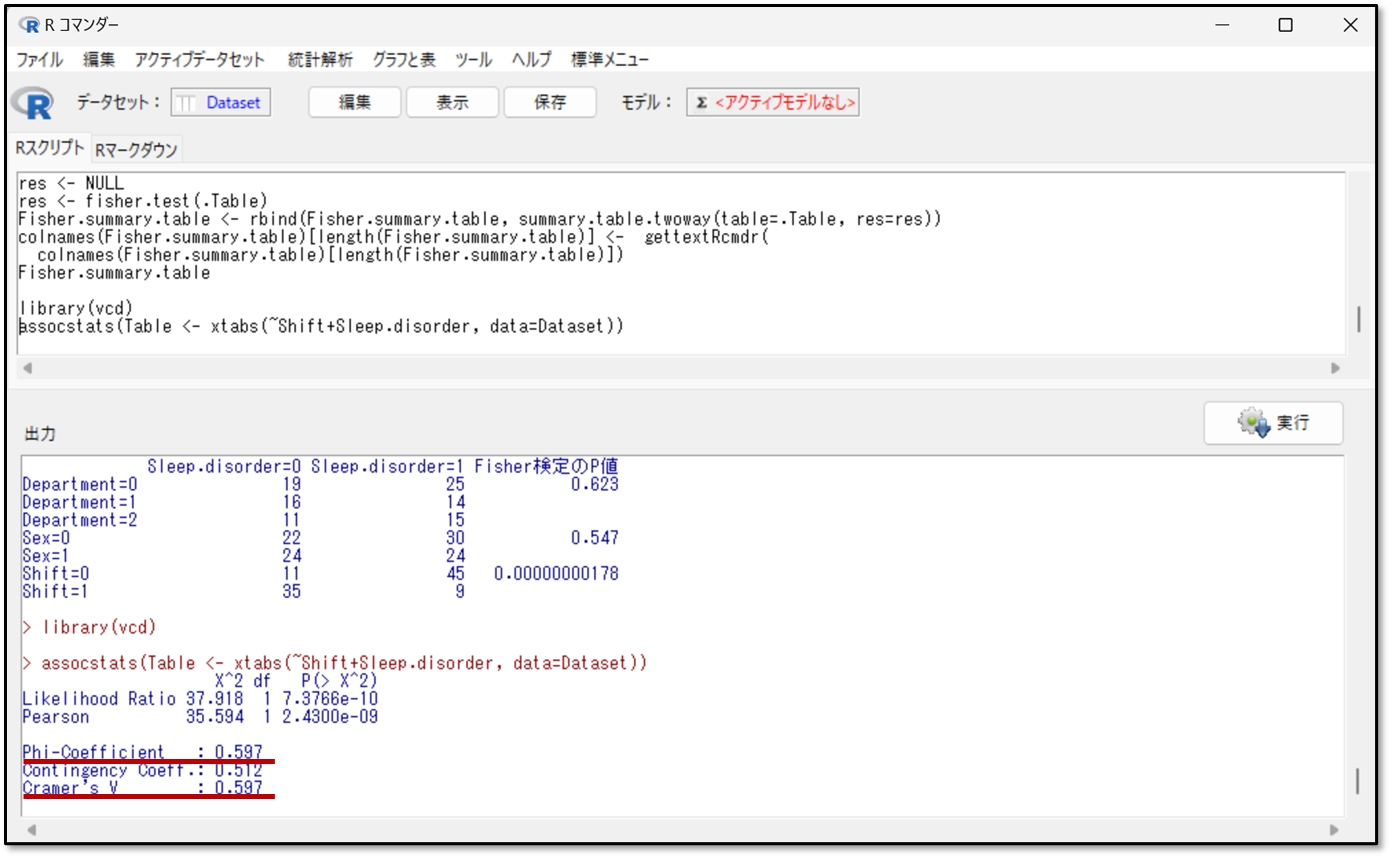
先ほどのおさらいですが、2×2の分割表であればφ係数を、2×2の分割表以外はクラメールのV係数を選択します。連関係数は0に近い程関係が小さく、1に近いほど関係が大きいとされており、判断基準の目安は、連関係数が0.2未満で関係がほとんどなく、0.7以上でかなり強い関連があるとされています。
今回の場合だと、φ係数(Phi-Coefficient)が0.597、クラメールのV係数(Cramer’s V)が0.597なので、強い関連があると判断します。
まとめ
分割表の検定は、カテゴリカルデータ(名義尺度や順序尺度などの質的データ)の分析に使用される手法です。看護研究において使用されることが多く、看護研究のデータ解析の基本となっています。
この手法を適切に理解し使用することで、より信頼性の高い研究結果を導くことができるため、この機会にしっかりと理解していきましょう!
この記事を通じて基本的な理解を深め、実際のデータ解析に活かしていただければ幸いです。
今回は分割表の検定について【実践編】として、実際に検定を行う方法を解説しました。分割表の検定の概要を知りたい方は下記の【概要編】参照してください。

コメント