








Last Updated on 2025年2月17日 by カメさん

こんにちは!看護師のカメさん(@49_kame)です。
この記事は5~6分で読めます。
前回は“対応のないデータ”の2標本の差の検定を行う方法を解説しました。今回は前回同様に統計解析ソフトEZRを使用して実際に2標本の差の検定を行う方法を解説します。
※基本事項の解説は前回と同様ですので、具体的な検定方法を確認したい方は目次の「EZRで行う2標本の差の検定手順(“対応のない”データ)」から参照してください。
科学的研究やビジネス分野における分析において、2つのグループ間の平均値に差があるかどうかを明らかにすることは、多くの意思決定の基盤となります。今回の記事では、初心者でも理解しやすいように、EZRを用いた2標本の差の検定(対応のあるデータ)の基本的な手順と結果の解釈方法を、具体例を交えて詳しく解説していきます。統計的な手法に新しい一歩を踏み出すあなたを、わかりやすくガイドできればと思います。
このブログでは統計解析ソフトしてEZRを使用しています。EZRは無料かつ精度も高い統計解析ソフトであるためおすすめです。EZRの概要とインストール方法については【EZRの概要とインストール方法】看護研究を変える!EZRで効率的な統計解析を参照してください。
2標本の差の検定とは?
2標本の差の検定は、対応のない(独立した)グループまたは対応のあるグループの平均値に統計的に有意な差があるかどうかを評価する方法です。この手法は科学的研究における仮説検定に広く用いられています。事前に帰無仮説と対立仮説を設定し、検定を行います。
2標本の差の検定の概要を知りたい方は【t検定ってなに?:概要編】看護研究の疑問を解決「2群の差を比較しよう」を参照してください。
帰無仮説と対立仮説とは?
帰無仮説と対立仮説は統計解析の際に立てる仮説のことです。帰無仮説は否定(棄却)されることを期待して設定され、対立仮説は採択されることを期待されて設定されます。統計解析では一般的に、p<0.05の場合に帰無仮説が棄却されます。
例えば、2群の差を調べる場合は、帰無仮説「差が無い」と対立仮説「差があるの2つの仮説」を立てます。差があるか知りたい検定なので、帰無仮説である差が無いが否定されることが期待されています。つまり差がない仮説が否定されて差がある結果になったらいいなあということです。
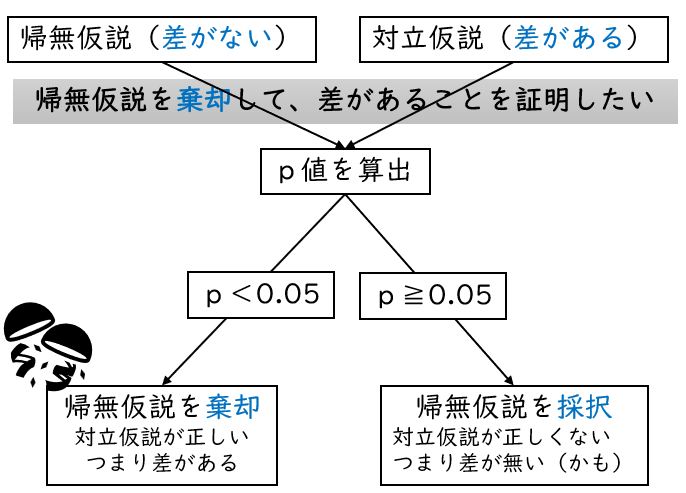
そして結果を統計解析を使用して確認します。p値が0.05未満であれば、帰無仮説が棄却、つまり否定されます。帰無仮説 差がないという仮説が否定されたということは、2群には差があるあることが分かったということです。反対にpが0.05以上であれば、帰無仮説である、差が無いという仮説が選ばれてしまうので、2群には差が無かったという結果になります。
ここは、混乱してしまう人も多いと思うので、ゆっくり考えてみてください。
対応のないデータと対応のあるデータとは?
対応のないデータとは、互いに独立した2つのグループ間で比較が行われる場合です。また対応のあるデータは、同じ被験者が異なる条件下で測定されたデータなど、ペアで存在するデータを指します。
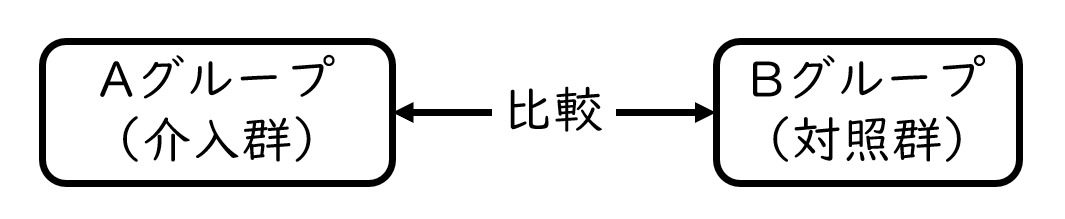
対応のないデータの2標本の差の検定とは?
対応のないデータを用いた2標本の差の検定とは、2つのグループからそれぞれ収集するデータを比較する分析のことです
例えば、介入群と対照群の2群を比較する分析などです
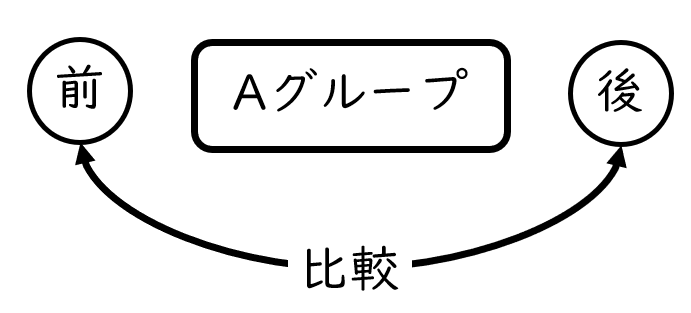
対応のあるデータの2標本の差の検定とは?
対応があるデータを用いた2標本の差の検定とは、1つのグループから収集する2つのデータを比較する分析のことです
例えば、1グループへの介入前後の点数の比較などです
2標本の差の検定には種類がある
2標本の差の検定には種類があり、以下の3つのポイントで決まります。
- ➀ 「対応のないデータ」or 「対応のあるデータ」
- ② 「正規分布」 or 「正規分布でない」
- ③ 「等分散する」or 「等分散しない」

収集したデータの特徴に合わせて分析方法を検討しよう。今回は対応のあるデータに焦点を当てて解説するよ。
EZRで行う2標本の差の検定手順(“対応のある”データ)
今回はEZRを使用して「対応のあるデータ」の2標本の差の検定について解説します。
今回使用するデモデータ
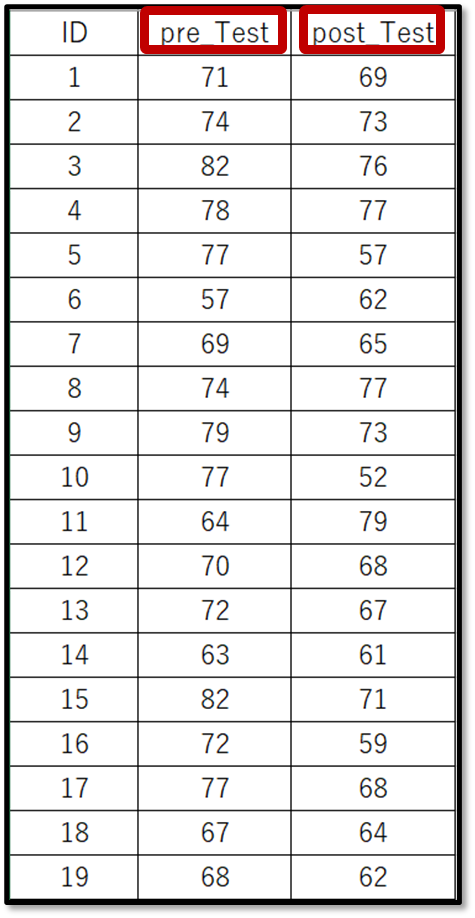
今回は下記のデモデータ(一部抜粋)を使用します。
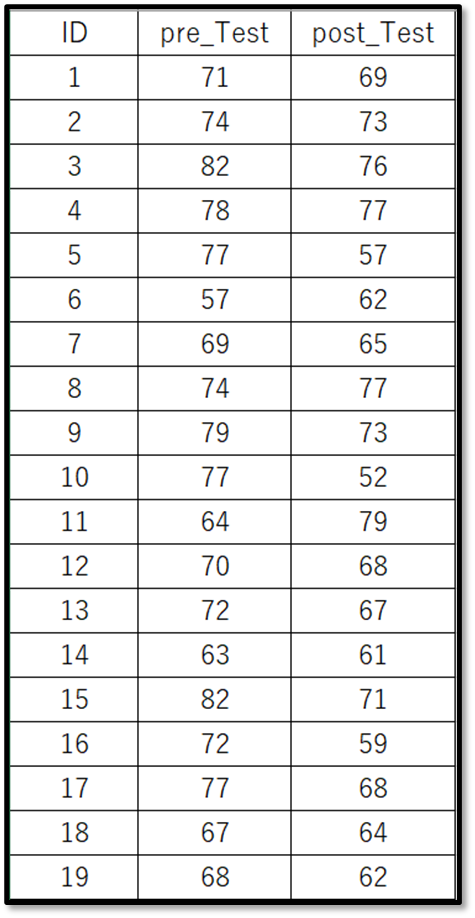
表示しているのは、デモデータの一部です。デモデータは下記からダウンロードできるので使ってみてください。
ランダム関数で作成しているため、今回の結果とズレが出るかもしれませんが、ご了承ください。
こちらのデモデータを読み込んだ後の段階から解説します。データの読み込み方法については、【統計解析ソフトにデータを入力】看護研究初めの一歩:EZRにデータセットを入力しよう!を参照してください。
あるグループの介入前後のテストの点数を比較します。介入前をプレテスト、介入後をポストテストと表現しています。
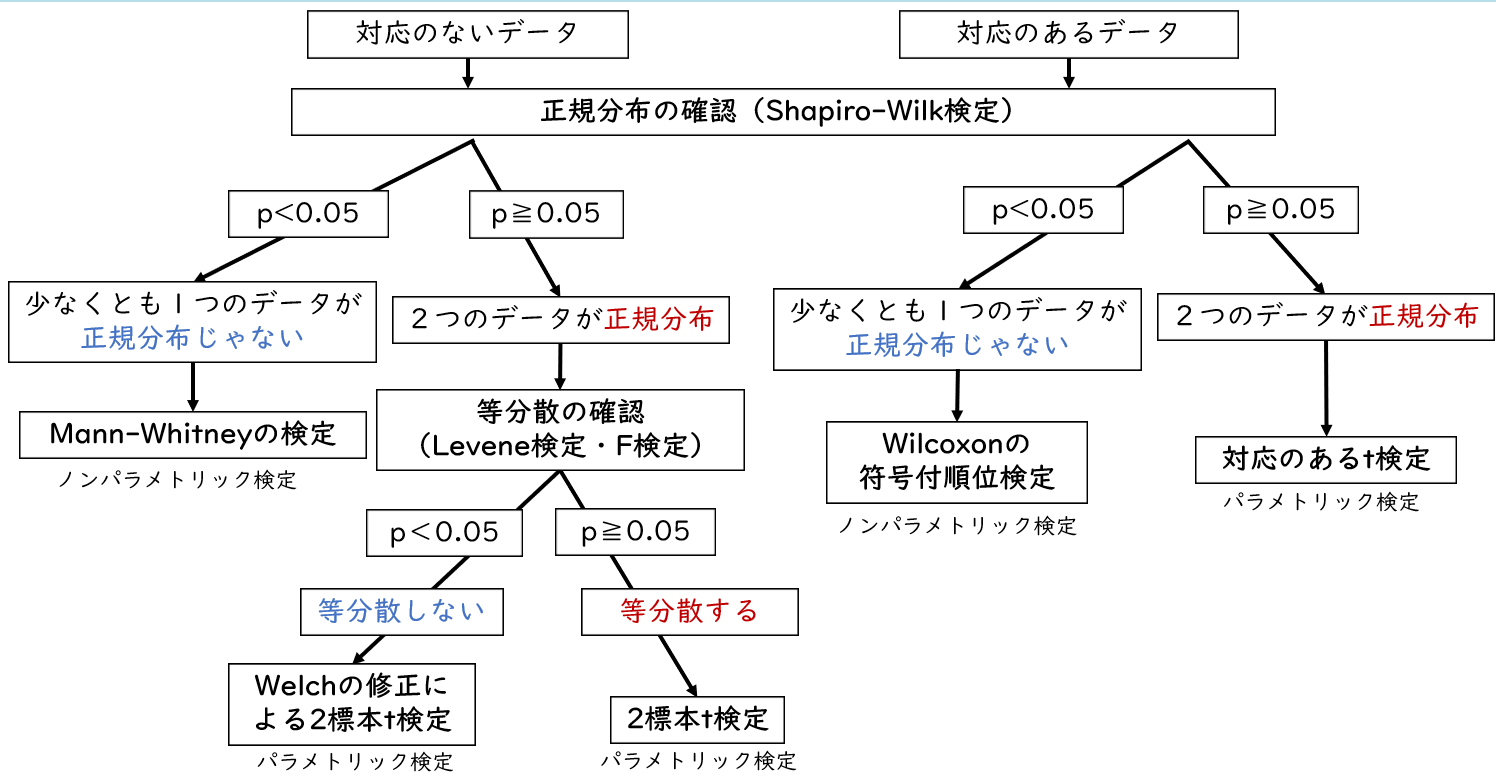
「対応のあるデータ」の2標本の差の検定実行手順
下記が2標本の差の検定の手順で、対応のないデータの2標本の差の検定について手順通りやってみたいと思います。今回は介入前と介入後のテストの点数(対応のあるデータ)の比較を行ってみたいと思います。
まずは介入前と介入後のテストの点数についてそれぞれ正規分布を確認します。今回は正規分布の確認手順は割愛します。詳しく知りたい方は【正規分布とは?:実践編】看護研究の疑問を解決「EZRで正規分布を確認しよう」を参照してください。
2標本ともに正規分布している場合
介入前テストのデータも、介入後のテストのデータも、どちらも正規分布している場合はパラメトリック検定である対応のあるt検定を選択します。
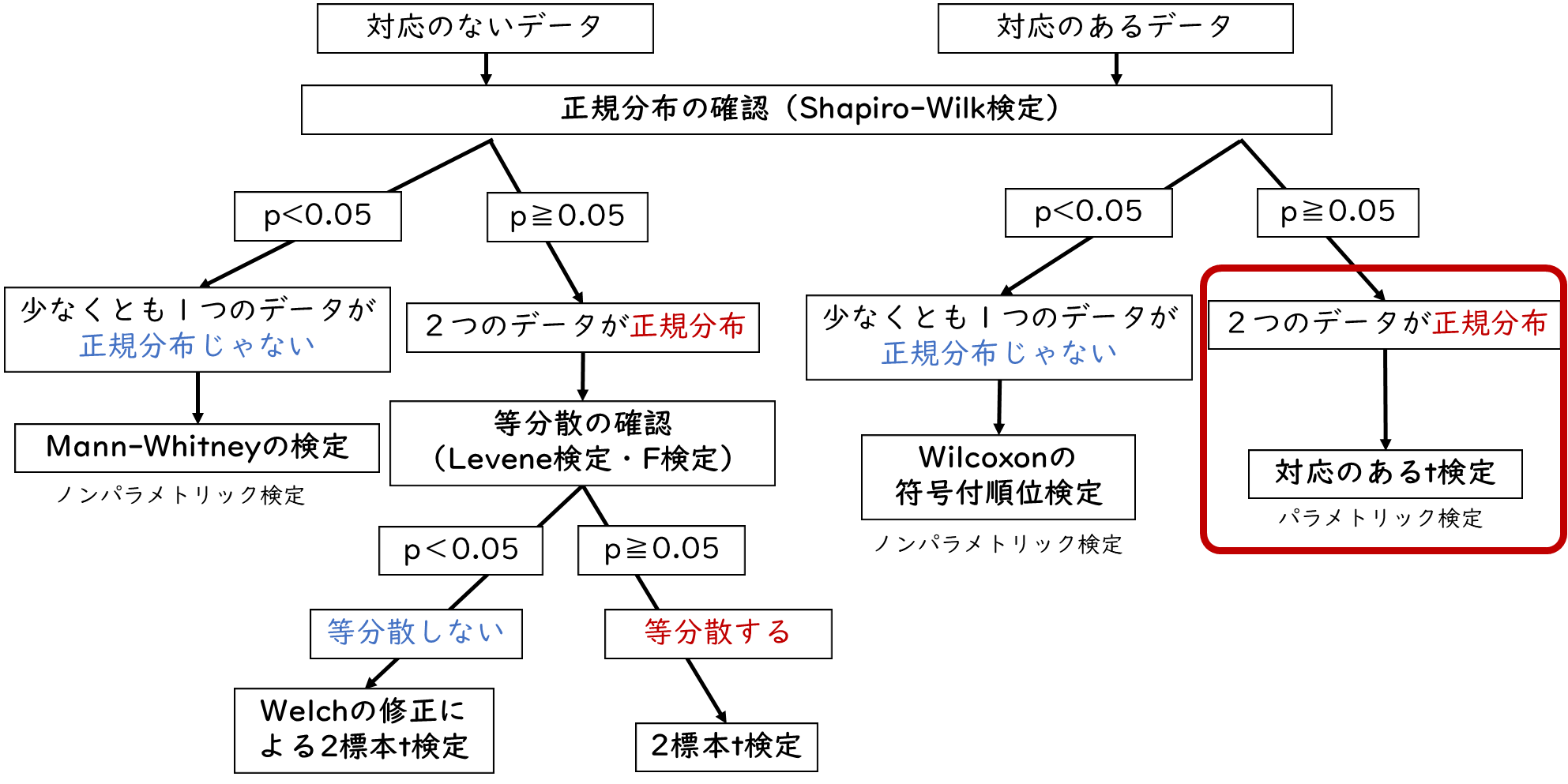
デモデータの中の「データ1」と記載されたデータが、どちらも正規分布するように調整したデータだよ。
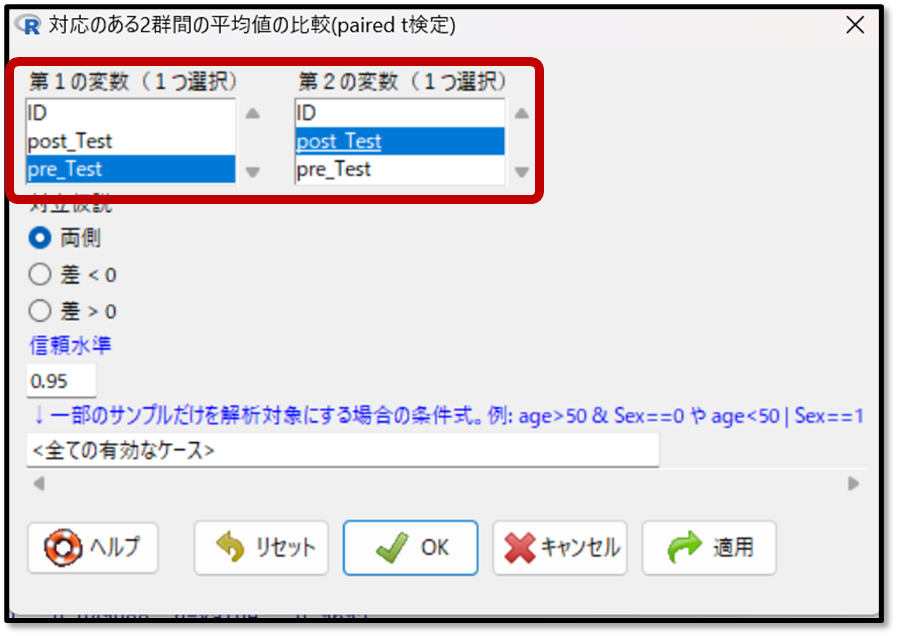
対応のあるt検定の方法を説明します。EZRの画面で「統計解析」→「連続変数の解析」→「対応のある2群間の平均値の比較(paired t検定)」を選択します。
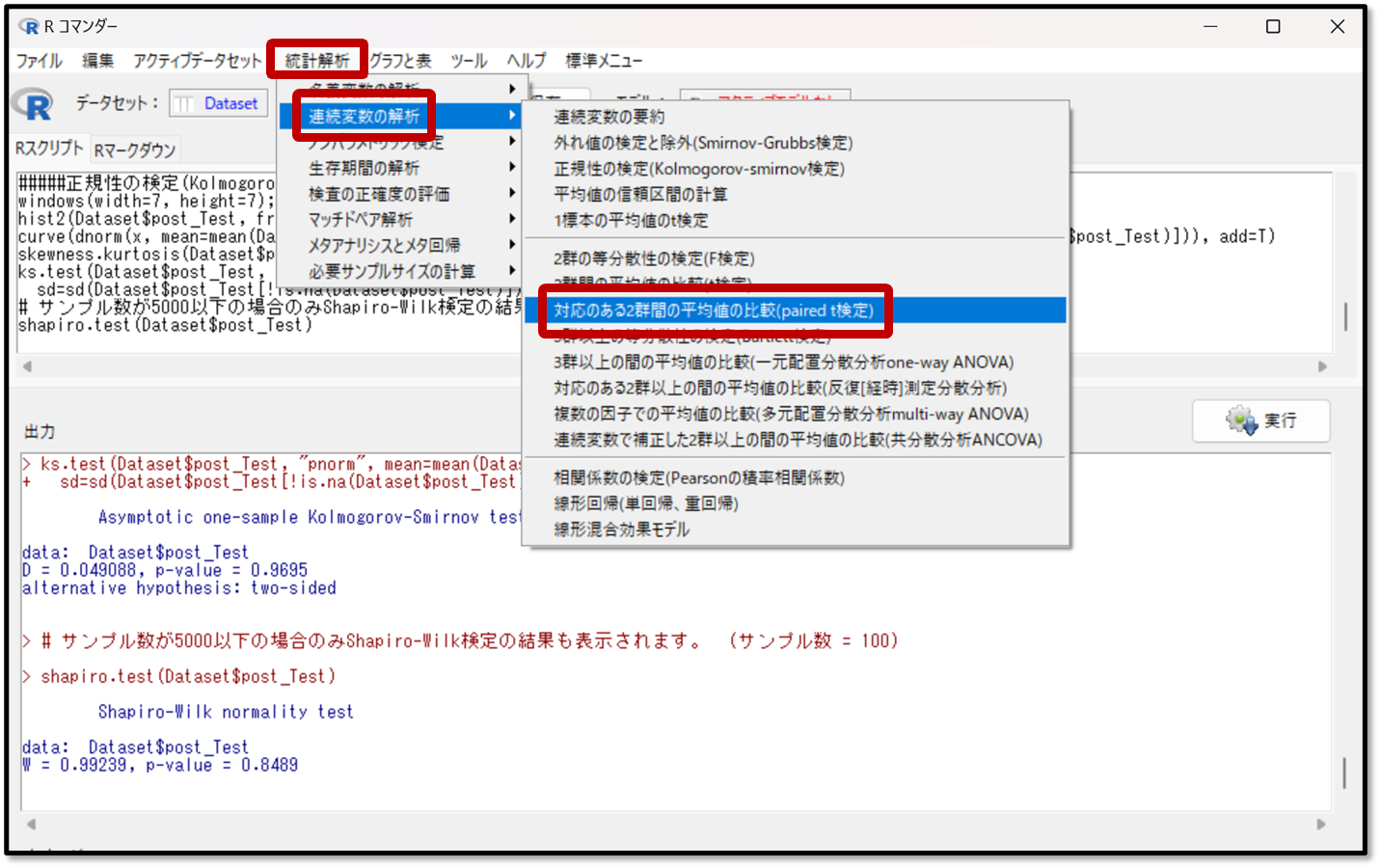
次に「対応のある2群間の平均値の比較」を行いたい変数として、1つ目の変数にプレテスト、2つ目の変数にポストテストを選択します。OKを押すと、対応のあるt検定の結果が算出されます。
下記が「対応のある2群間の平均値の比較(paired t検定)」の出力結果です。
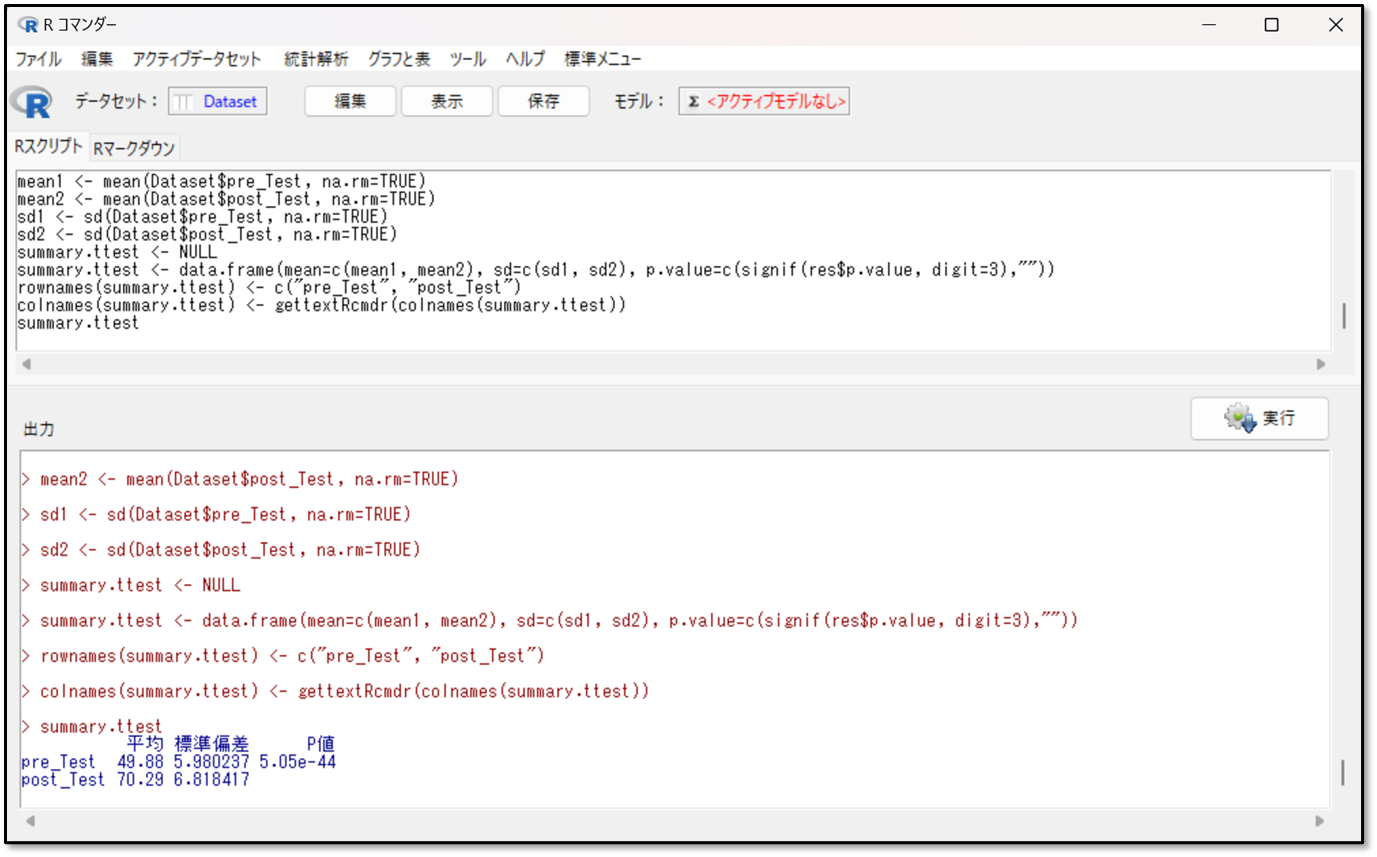
結果の見方は、まずは「平均値」「標準偏差」で各群の要約したデータを確認します。次に「p値」を確認し、p値がp<0.05であれば、有意な差があると判断します。
今回の結果を改めて見てみましょう。

プレテストの平均値が49.88、ばらつきである標準偏差が5.98程度、ポストテストの平均値が70.29、標準偏差が、6.82程度でした。
p値を見てみましょう。p値にイーのような文字が記載されています。これは「ネイピア数」と呼ばれるものです。5.05e(ネイピア数)-44は、5.05×10の-44乗を表すので、p値は0.000・・・505となりかなり小さな値であることが分かります。つまりp値は0.05未満であり、介入前後のプレテスト、ポストテストには有意な差があると判断します。そのため介入がテストの点数に影響を与えている可能性が高いと判断します。
2標本の少なくとも1つが正規分布していない場合
次にプレテストとポストテストのデータのうち、少なくとも1つのデータが正規分布していない場合について解説します。2つのデータのうち、少なくともどちらか一方のデータが正規分布していない場合は、ノンパラメトリック検定であるWilcoxonの符号付順位検定を選択します。
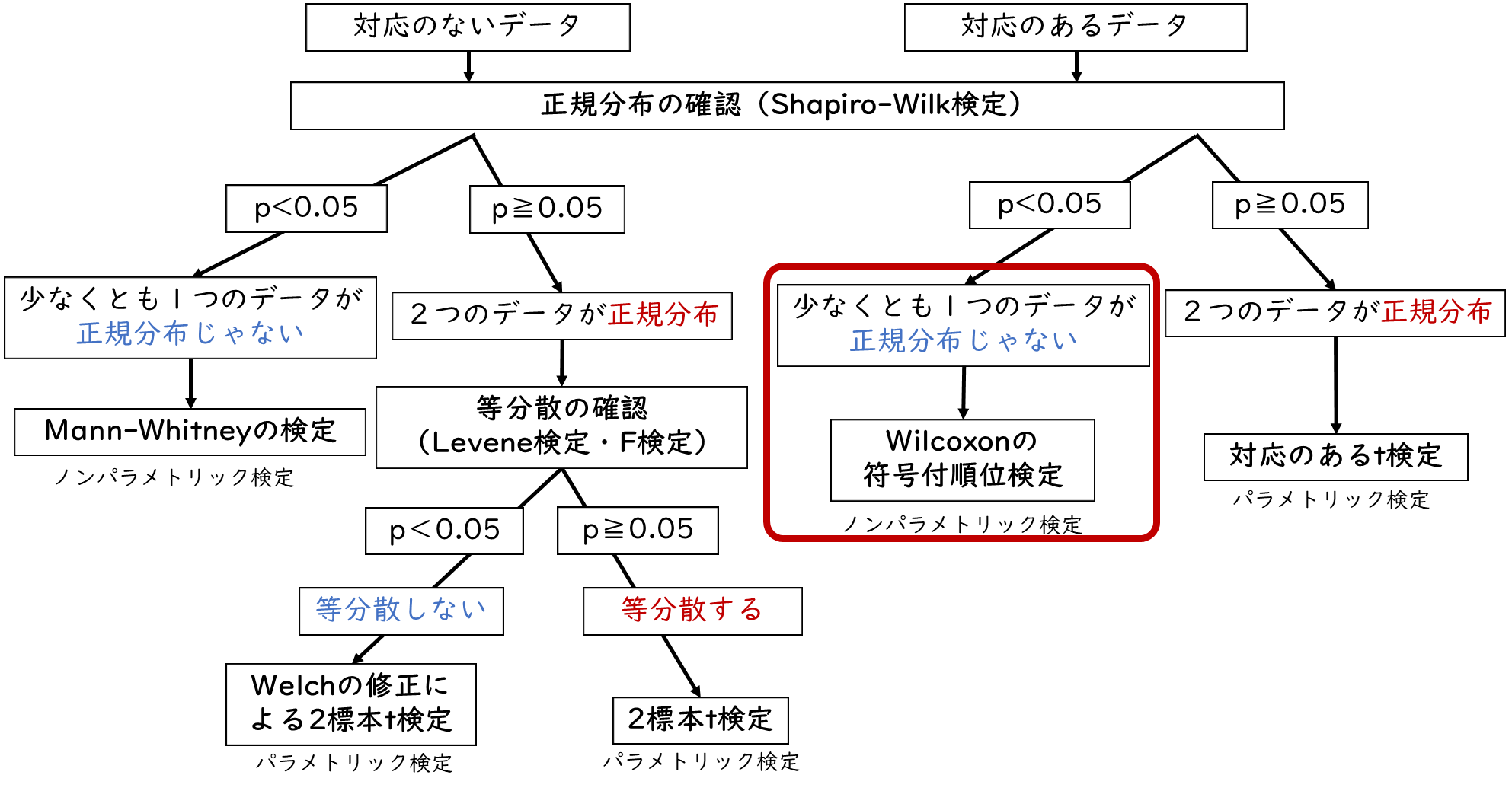
デモデータの中の「データ2」と記載されたデータが、どちらか一方が正規分布しないように調整したデータだよ。
Wilcoxonの符号付順位検定の方法を解説します。EZRの画面で「統計解析」→「連続変数の解析」→「対応のある2群間の比較( Wilcoxonの符号付順位和検定)」を選択します。
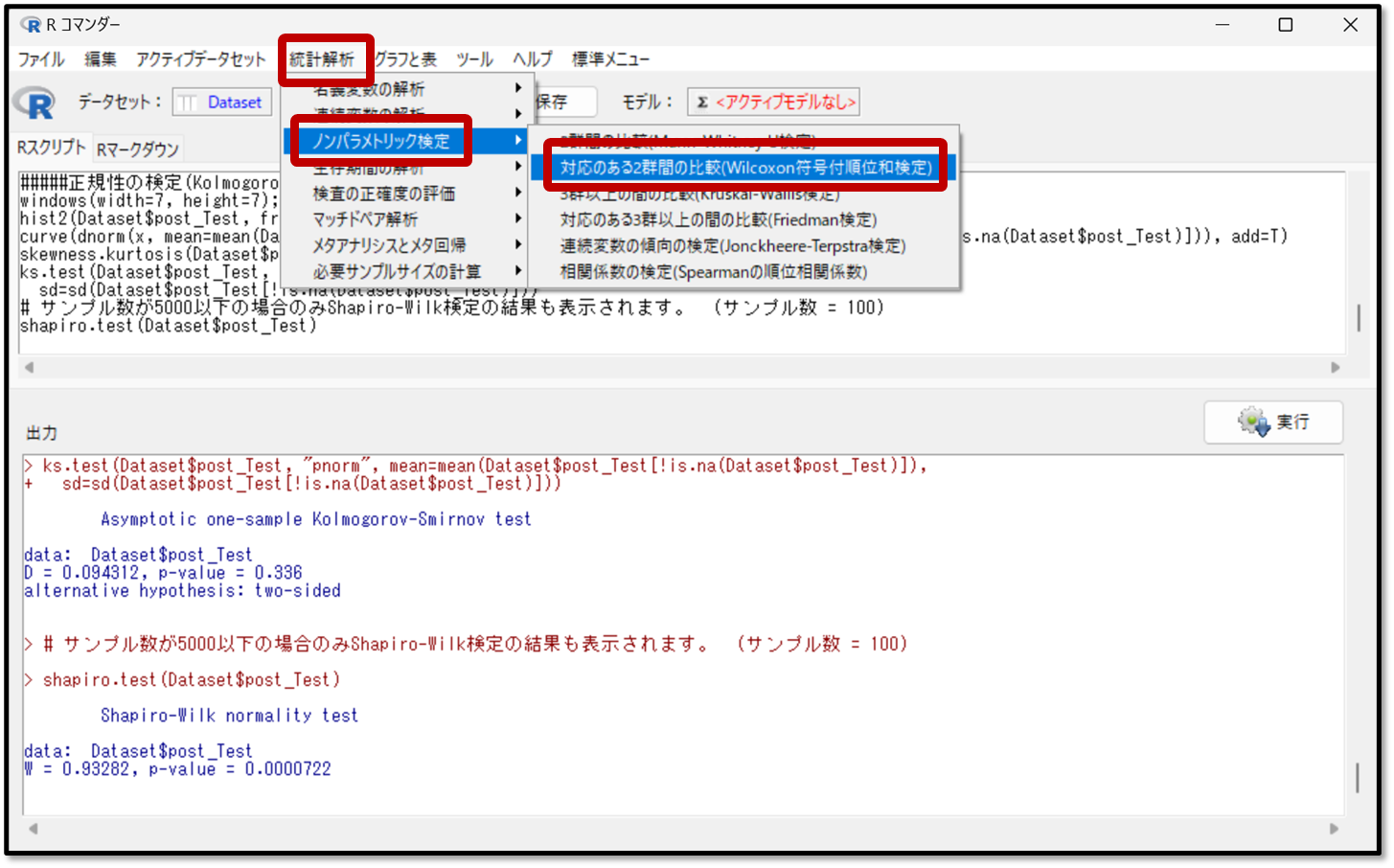
続いて「対応のある2群間の比較( Wilcoxonの符号付順位和検定)」の変数を選択します。1つ目の変数としてプレテストを選択し、2つ目の変数としてポストテストを選択します。
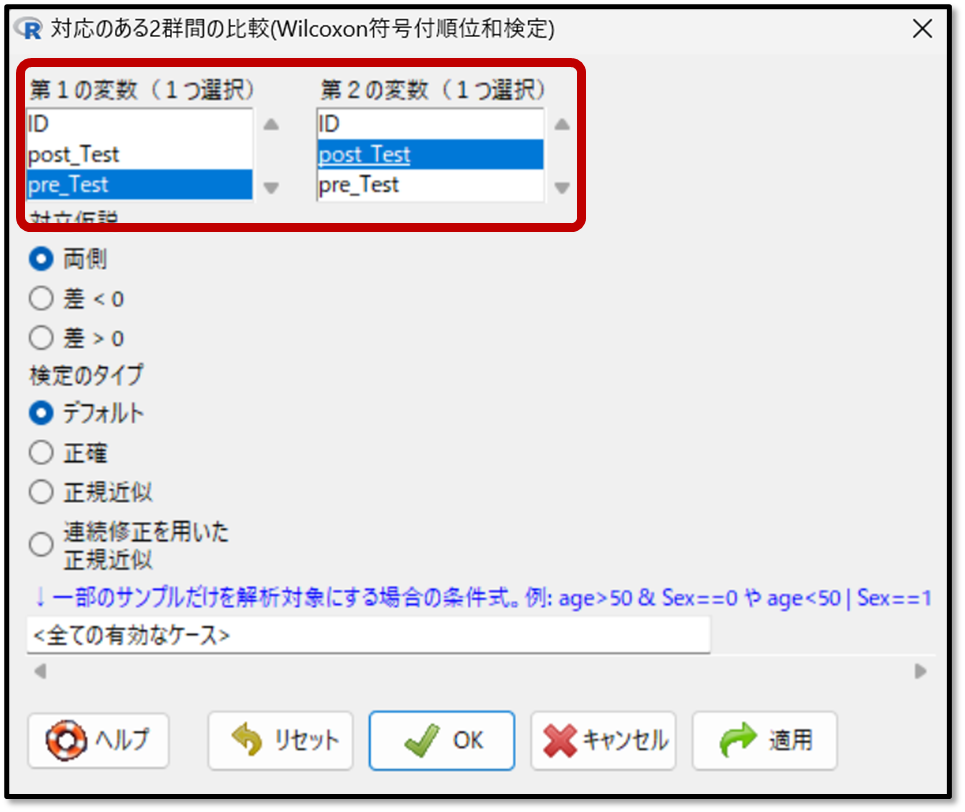
これが「 Wilcoxonの符号付順位和検定」の出力結果です。
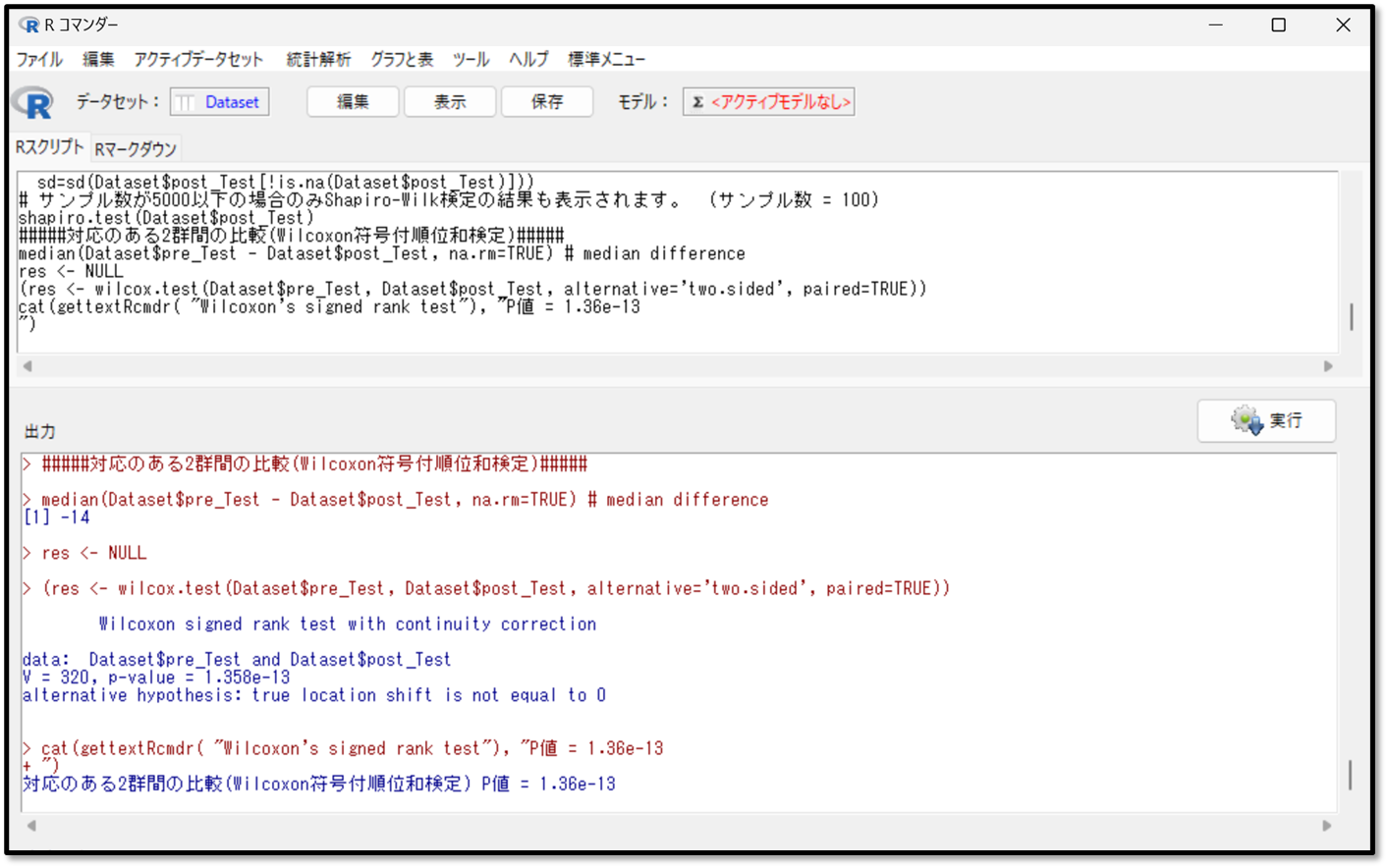
結果の見方ですが、出力されているのはp値だけなので「p値」を確認します。p値がp<0.05であれば、有意な差があると判断します。

今回は「p値」が1.358e-13と出力されました。これは先ほど同様、ネイピア数と呼ばれるもので1.358×「10の-13乗」を表します。つまりP=0.0000000000001358ということです。この結果より、プレテストとポストテストの間に有意な差があると判断します。
この出力結果にある通り、「Wilcoxonの符号付順位和検定」ではデータの要約(中央値など)は出力されません。そのため、要約したデータを算出するための追加の操作が必要になります
さっきのパラメトリック法の際は、データの要約(平均値・標準偏差)は算出されていたね
別操作でデータの要約を行う
EZRで上記の Wilcoxonの符号付順位和検定を行った場合は、中央値などデータを要約した値が出力されません。そのためデータの要約が別操作で必要となります
EZRの画面からデータの要約を行う方法を簡単に解説します。まずは「統計解析」→「連続変数の解析」→「連続変数の要約」を選択します。
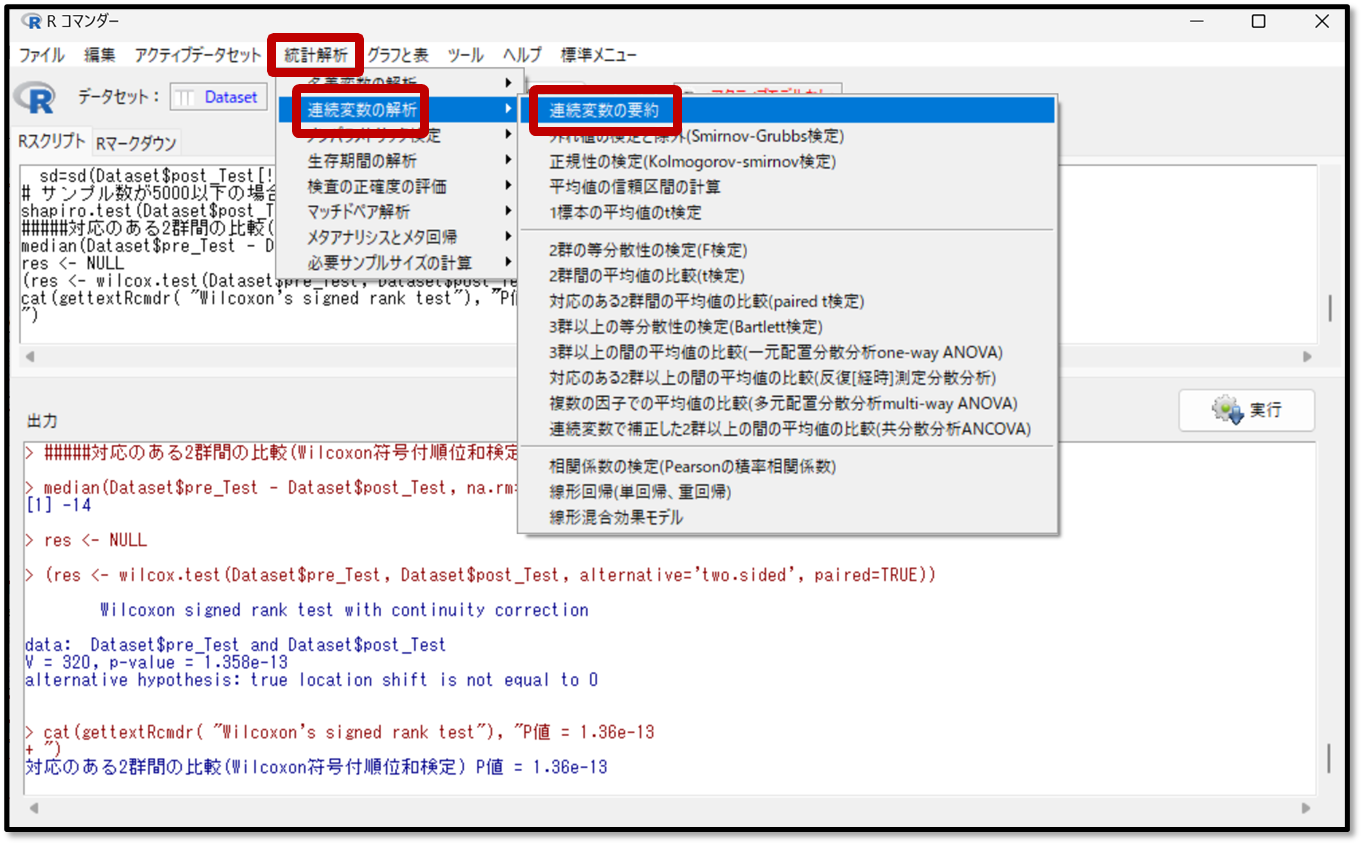
次の画面で要約したい変数としてプレテストとポストテストを選択します。データの要約では平均や標準偏差も見れます。今回は正規分布していないデータに対して行ったWilcoxonの符号付順位和検定の追加操作として行っているので、分位点(中央値や四分位範囲を出力)に✓が入っていることを確認しましょう。
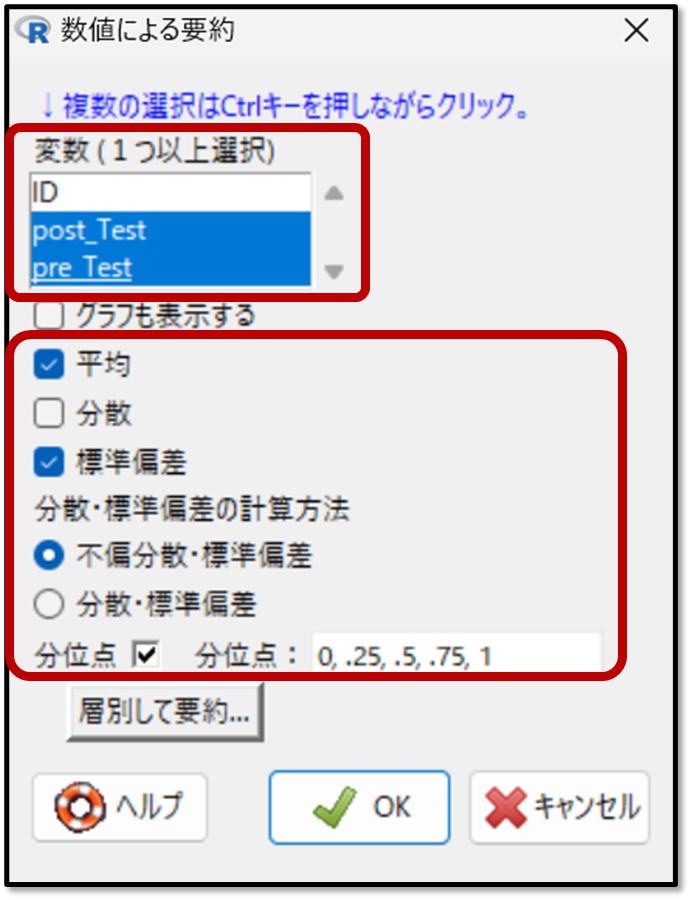
下記がデータを要約した出力結果です。
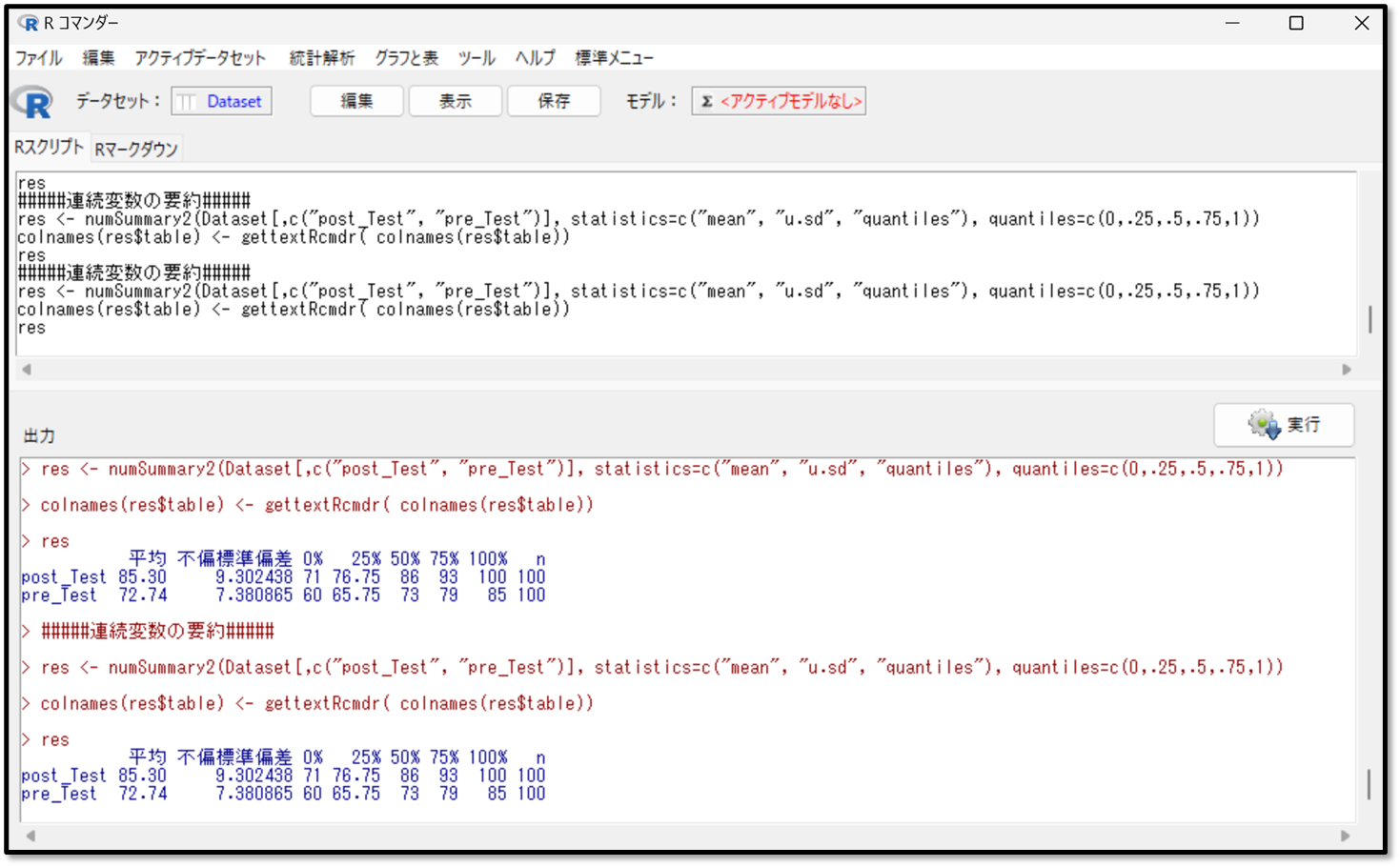
一般的な要約したデータの結果の見方ですが、正規分布に従う場合は、代表値は「平均」を、データのばらつきは「標準偏差」を確認します。正規分布に従わない場合は、代表値は「中央値(50%) 」、データのばらつきは「四分位範囲」を確認します。
結果は、データの分布にあった数値を確認するようにしよう!
それでは結果を見てみましょう。

今回は正規分布していないデータに対して行ったWilcoxonの符号付順位和検定の追加操作のため、中央値と四分位範囲を確認します。50%と記載されているのが中央値であり、25%と75%と記載されているのが四分位範囲となります。
まとめ
今回の記事が参考になれば幸いです。また、本記事で紹介した統計手法を活用することで、より信頼性の高い研究結果を得ることが可能となります。対応のある2標本の差の検定を理解し実践することは、データに隠された真実を解き明かす鍵となり得ます。特に、医学研究や社会科学の分野では、時間経過に伴う変化や介入の効果を正確に評価することが重要です。EZRを用いた分析は、そのプロセスを容易にし、研究の品質向上に貢献します。あなたの収集したデータから新たな知見が引き出され、社会に貢献する研究を展開していくことを心から願っています。
今回は2標本の差の検定(“対応のある”データ)を実際に行う方法を解説しました。2標本の差の検定の概要を知りたい方は下記を参照してください。


コメント