








Last Updated on 2026年4月9日 by カメさん

こんにちは!看護師のカメさん(@49_kame)です。
この記事は10分程度で読めます。
今回は統計解析ソフトEZRを使用して実際に多重ロジスティック回帰分析を行う方法を解説します。
多重ロジスティック回帰分析は、異なる要因が結果にどのように影響を与えるかを明らかにするために使用されます。本記事では、具体的な分析手順の説明だけでなく、得られた結果の読み解き方まで詳しく説明していきます。この方法を理解することで、看護研究におけるデータ分析の基礎を固めることができ、研究成果をより深く、効果的に評価することができるようになるでしょう。
デモデータを使用して実際に多重ロジスティック回帰分析を行う手順を一歩一歩、初学者でも理解できるように丁寧に解説していくのでよろしくお願いします。
この記事を通じて、看護研究における統計分析の悩みを解決する一助になれば幸いです。
このブログでは統計解析ソフトしてEZRを使用しています。EZRは無料かつ精度も高い統計解析ソフトであるためおすすめです。EZRの概要とインストール方法については【EZRの概要とインストール方法】看護研究を変える!EZRで効率的な統計解析を参照してください。
はじめに
まずは多重ロジスティック回帰分析を行うための基礎知識から解説します。重回帰分析の解説と重複する部分もあるよ。先に具体的な手順を知りたい方は、「多重ロジスティック回帰分析の検定手順」から参照してね。
多重ロジスティック回帰分析の概要を知りたい方は【多重ロジスティック回帰分析:概要編】看護研究の疑問を解決「因果関係を調査しよう」を参照してください。
基本知識:説明変数と目的変数
多重ロジスティック回帰分析を理解する上で、まずは説明変数と目的変数を理解することが重要となるため、先に解説します。そもそも変数とは数量のことです。数学でいうXとかYのことです。医療統計で良く出てくる変数は体重や身長、テストの得点などです。
まず説明変数について解説します。説明変数とは因果関係の中で原因になる変数のことです。独立変数とも呼ばれます。
説明変数は、「目的変数を説明する変数」なので、「説明」変数と呼ばれるよ
続いて目的変数について解説します。目的変数とは物事の結果になる変数です。従属変数とも呼ばれます。
目的変数は、「説明変数から予測したい結果、つまり目的のこと」だから「目的」変数と呼ばれるよ
例えば、下記のように食事量が原因で体重が変化するかどうかを検討したい場合は、説明変数が食事量で、目的変数が体重になります。このように、研究では説明変数が本当に目的変数を説明しているかを検討します。

まとめると、説明変数は目的変数の変動を説明するために使用される変数です。そして、目的変数は分析の結果予測したいまたは説明したい変数です。
基本知識:回帰式とは?
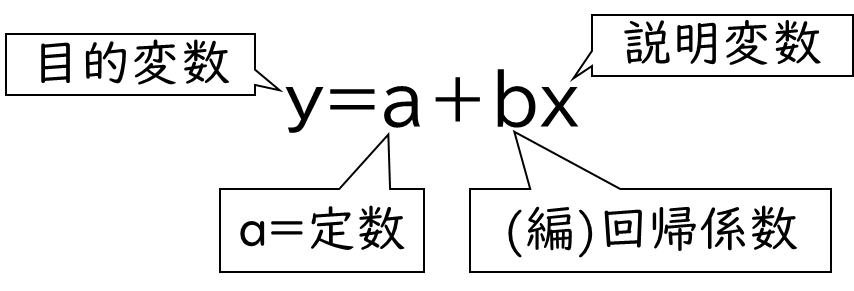
回帰分析では、回帰式を求めることで因果関係を分析することができます。回帰式とはy=a+bxの式のことです。これは原因である説明変数と結果である目的変数の因果関係を表す関係式のことです。
回帰分析はy=a+bx で表現します。そして多重ロジスティック回帰分析はy=a+b₁x₁+b₂x₂・・・です。多重ロジスティック回帰分析は説明変数が複数あるので、説明変数xを増やして表現します。
下記の図のようにYが目的変数、aが定数、bが回帰係数と呼ばれるもので、xが説明変数です。回帰係数とは説明変数の影響の大きさです。
多重ロジスティック回帰分析とは?
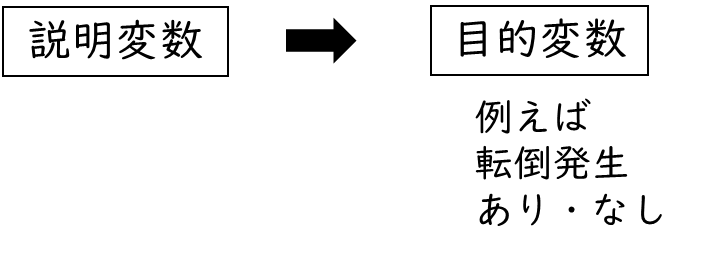
それでは本題に移ります。多重ロジスティック回帰分析とは、複数の説明変数から、2値の目的変数が起こる確率を予測する方法です。2値とは「転倒の有無」など、答えが2つしかない値のことです。
下記の図のように、説明変数が2値の目的変数に影響があるかを検討するのが多重ロジスティック回帰分析です。
重回帰分析との違い
重回帰分析との違いについても解説します。重回帰分析と異なる点は目的変数です。
重回帰分析も、多重ロジスティック回帰分析も、どちらも複数の説明変数から目的変数を予測する検定です。しかし下記の図のように重回帰分析の説明変数は連続変数(量的変数)であり、多重ロジスティック回帰分析の説明変数は2値データ(質的変数)という違いがあります。量的変数とは数値として計算できる変数で、質的変数とは分類に意味のある変数です。
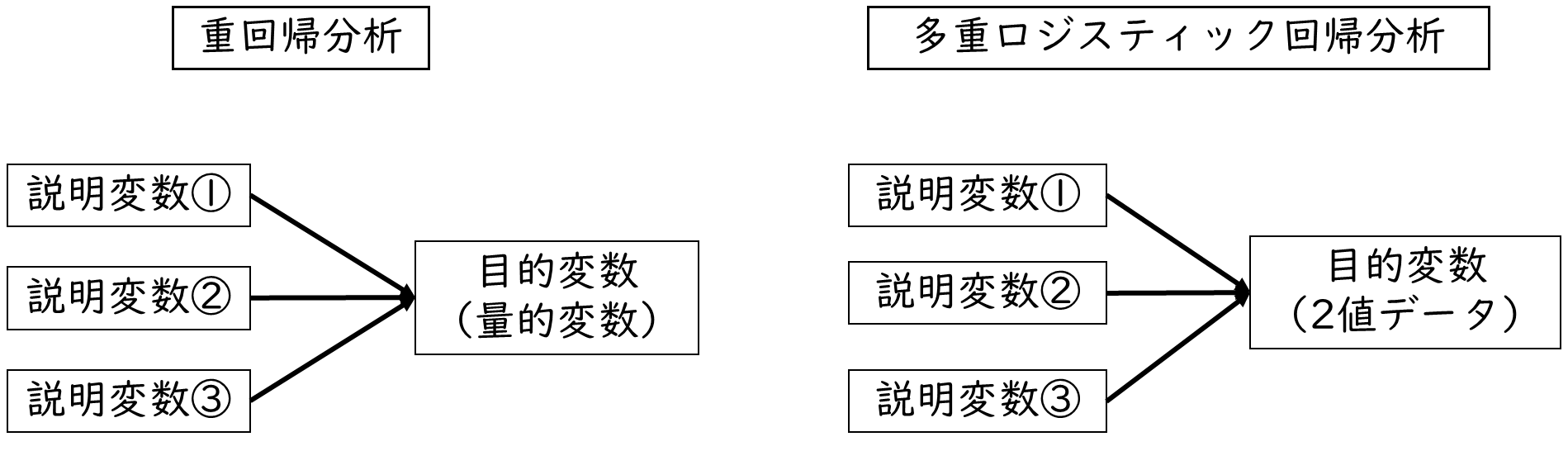
2値データは「0-1型データ」や「ダミー変数」と呼ばれることもあるよ。2値データは、例えば「疾患あり・なし」、「学習能力が高い・低い」などのデータだよ。
質的変数を統計ソフトに読み込む方法
2値データのような質的変数は、統計解析ソフトに読み込む前にダミー変数に変換する必要があります。ダミー変数とは、「男・女」など分類のみに意味を持つ質的変数を0と1に変換した変数のことです。
例えば、男女の違いであれば「男:0」「女:1」と変換して分析します。また転倒あり・なしであれば、「転倒なし:0」「転倒あり:1」などです。ちなみに、2つ以上の質的データでもダミー変数は使用可能です。例えば、グループA・B・Cであれば「グループA:0」「グループB:1」「グループC:2」などに変換します。
詳しくは【ダミー変数とは?】看護研究の疑問を解決「多変量解析で質的変数を使用する方法を解説」を参照してください。
ダミー変数を扱う上での注意点
ダミー変数を扱う上での重要な注意点が、どちらを0とするかは研究者が事前に決めるということです。ダミー変数では、解析前に基準となる0を研究者が決めます。
そのため、どちらを0としてどちらを1としたかをすぐに分かる形式で記載しておくことが重要です。例えば、Excelのシートの1つをデータの情報用として記載しておくなどです。
統計解析結果では0か1でしか表示されないため、解析結果を読む際に、ダミー変数の基準0を確認しながら解釈をする必要があるよ
多重ロジスティック回帰分析の基本手順
手順は下記の通りで、重回帰分析とほとんど同じです。
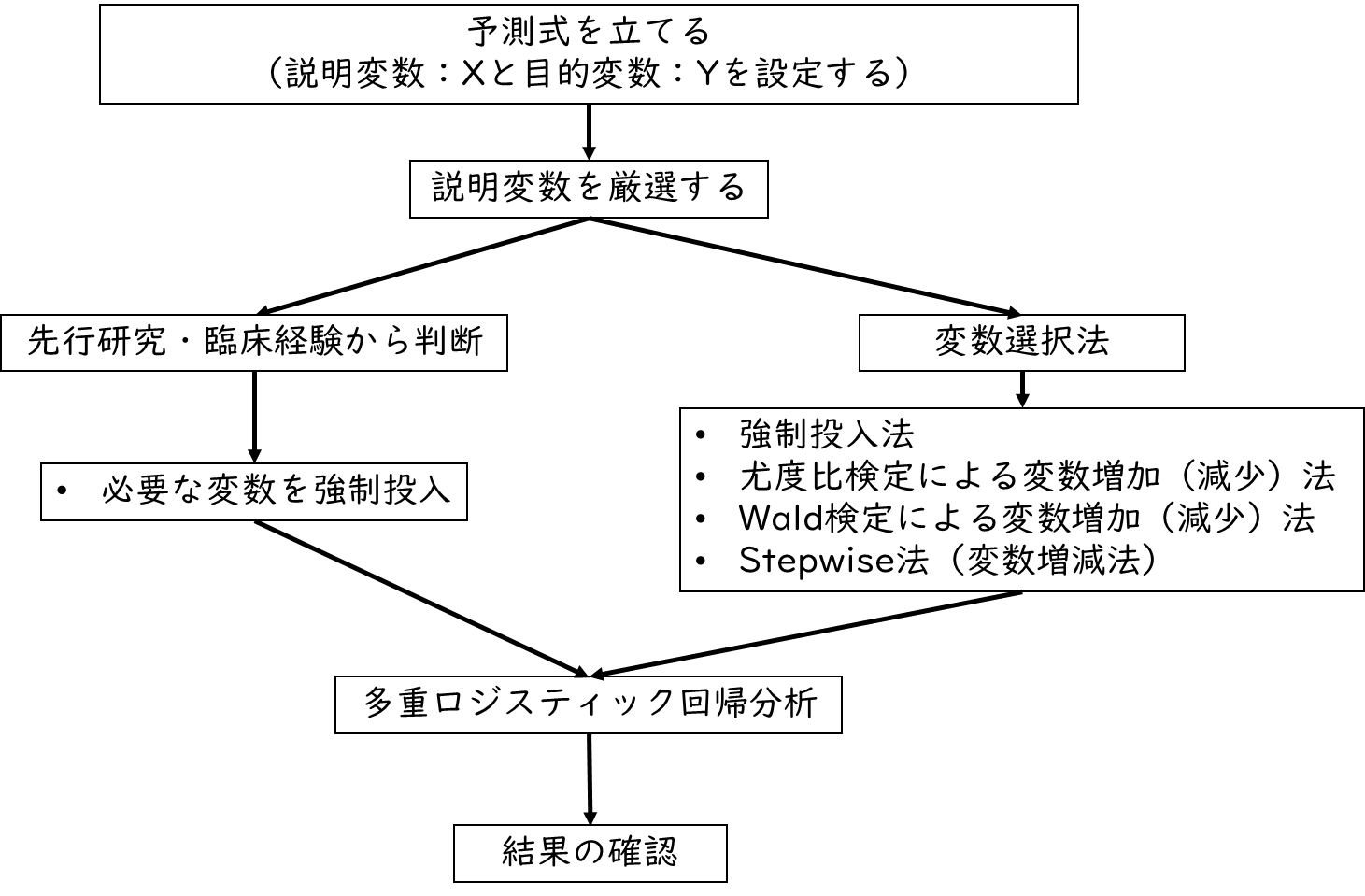
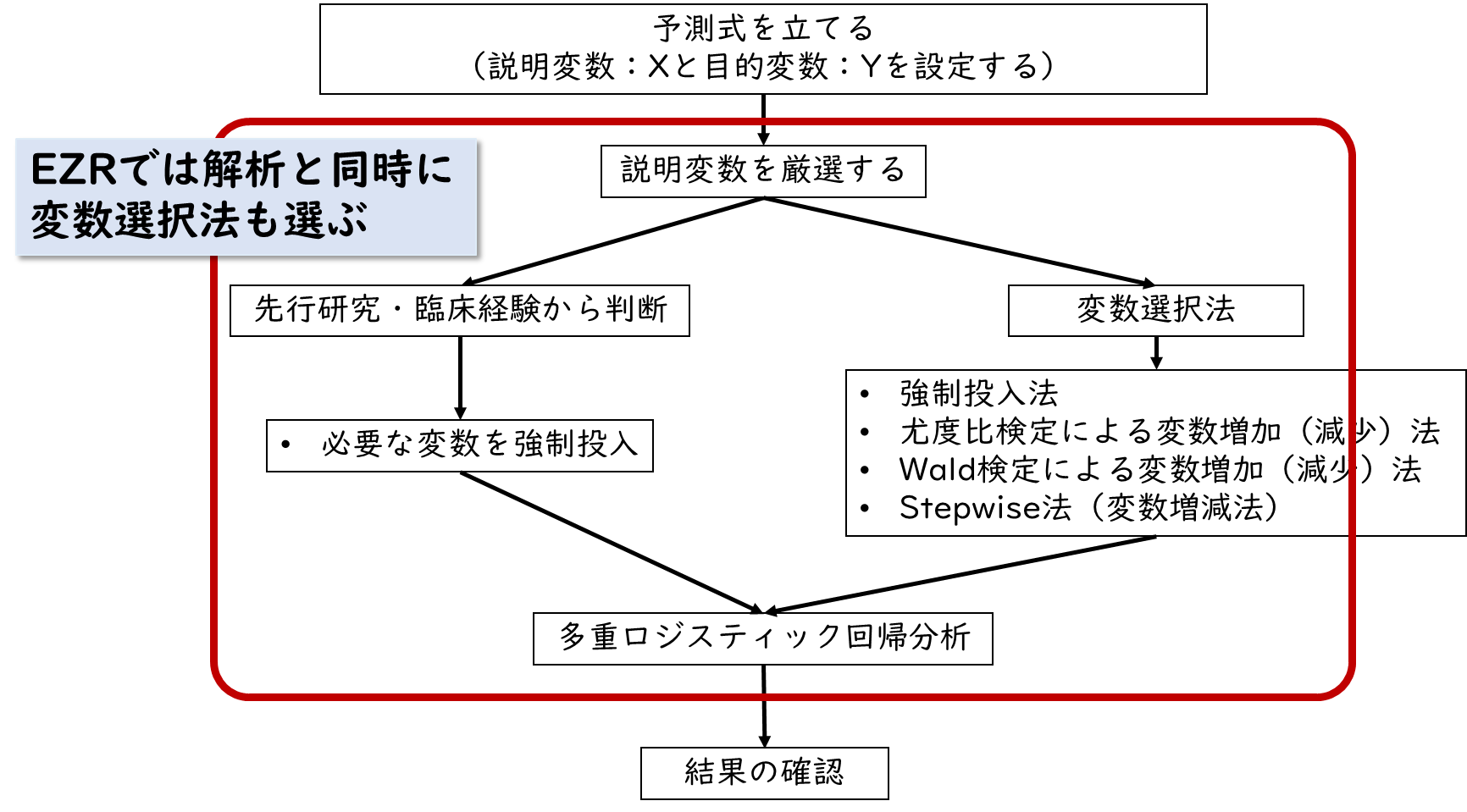
まずは説明変数(X)と目的変数(Y)を設定し、予測式(回帰式)を立てましょう。多重ロジスティック回帰分析では複数の説明変数(X)が設定されると思います。しかし全ての説明変数(X)を使用して分析する不都合があることもあるので、仮説で設定した説明変数(X)のうち、どれを使用するか厳選する作業が必要となります。
説明変数の選択方法は、変数選択法と呼ばれる方法で、統計的に変数を選択するとともに、先行研究・臨床経験から判断して必要な変数を強制投入します。下記で詳しく解説します。
変数選択法とは?
説明変数を選択するポイントは下記の2点です。
- 変数選択法を使用する
- 先行研究や臨床経験から必要な説明変数を選ぶ
このポイントは、どちらかではなく、どちらも重要となります。
まずは変数選択法の使用です。変数選択法は下記の4つがあります。
| ➀強制投入法 | すべての説明変数を投入して重回帰式を作る方法 |
| ②変数増加法 | 既存の重回帰式に新たな変数を追加していく方法 |
| ③変数減少法 | 既存の重回帰式から変数を減少させていく方法 |
| ④ステップワイズ法 (変数増減法) | 説明変数を入れたり抜いたりしながら最適なモデルを探す方法 |
変数選択法では、ステップワイズ法が推奨されています。しかし、多重ロジスティック回帰分析の場合、ステップワイズ法が使用できない統計ソフトもあります。その際は、尤度比(ゆうどひ)検定による変数増加(減少)法が推奨されています
次のポイントが、先行研究や臨床経験から必要な説明変数を選ぶことです。このポイントが特に重要です。変数選択法だけで説明変数を決定してしまうと、臨床的に意味のある変数が抜けてしまうことがあります。そのためあなたの臨床経験をもとに、目的変数に影響を与えると思われる変数を強制投入するようにしましょう。
多重ロジスティック回帰分析の説明変数には限度がある
多重ロジスティック回帰分析においても、重回帰分析と同様に投入可能な説明変数が限られています。通常は、n数÷10の説明変数が推奨されています。例えばn数が100人いるのであれば、投入できる変数は10個となります。
むやみに説明変数を投入しすぎると、変数同士が関係している可能性が高まります。これを多重共線性と呼びます。また回答が極端にすくない説明変数が存在する可能性も高まります。これらが解析結果に歪みを与える可能性があるので、説明変数を選択することは重要です。
EZRで行う多重ロジスティック回帰分析の検定手順
それではEZRを使用して多重ロジスティック回帰分析を行う方法について解説します。
今回使用するデモデータ
今回は下記のデモデータ(一部抜粋)を使用します。
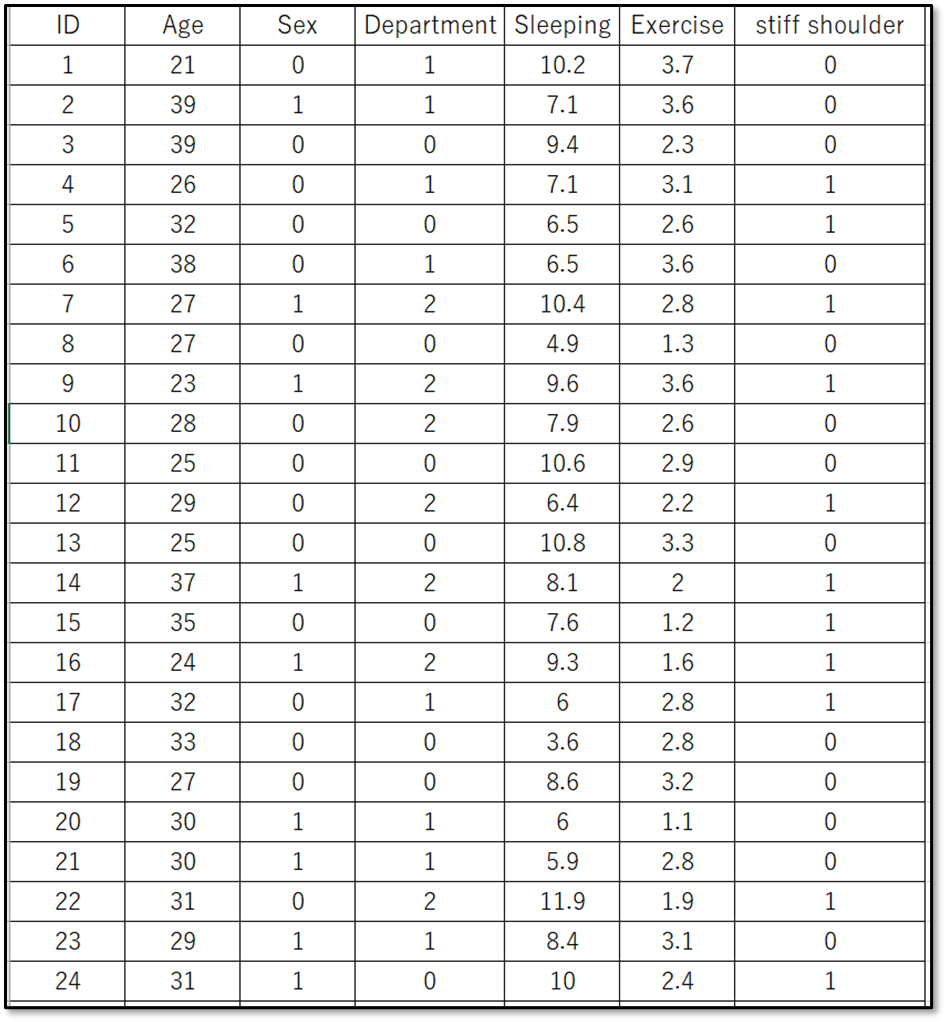
表示しているのは、デモデータの一部です。デモデータは下記からダウンロードできるので使ってみてください。
ランダム関数で作成しているため、今回の結果とズレが出るかもしれませんが、ご了承ください。
こちらのデモデータを読み込んだ後の段階から解説します。データの読み込み方法については【統計解析ソフトにデータを入力】看護研究初めの一歩:EZRにデータセットを入力しよう!を参照してください。
➀まずは予測式を立てる
多重ロジスティック回帰分析では、まず予測式(目的変数と説明変数の設定)を立てることから始めます。
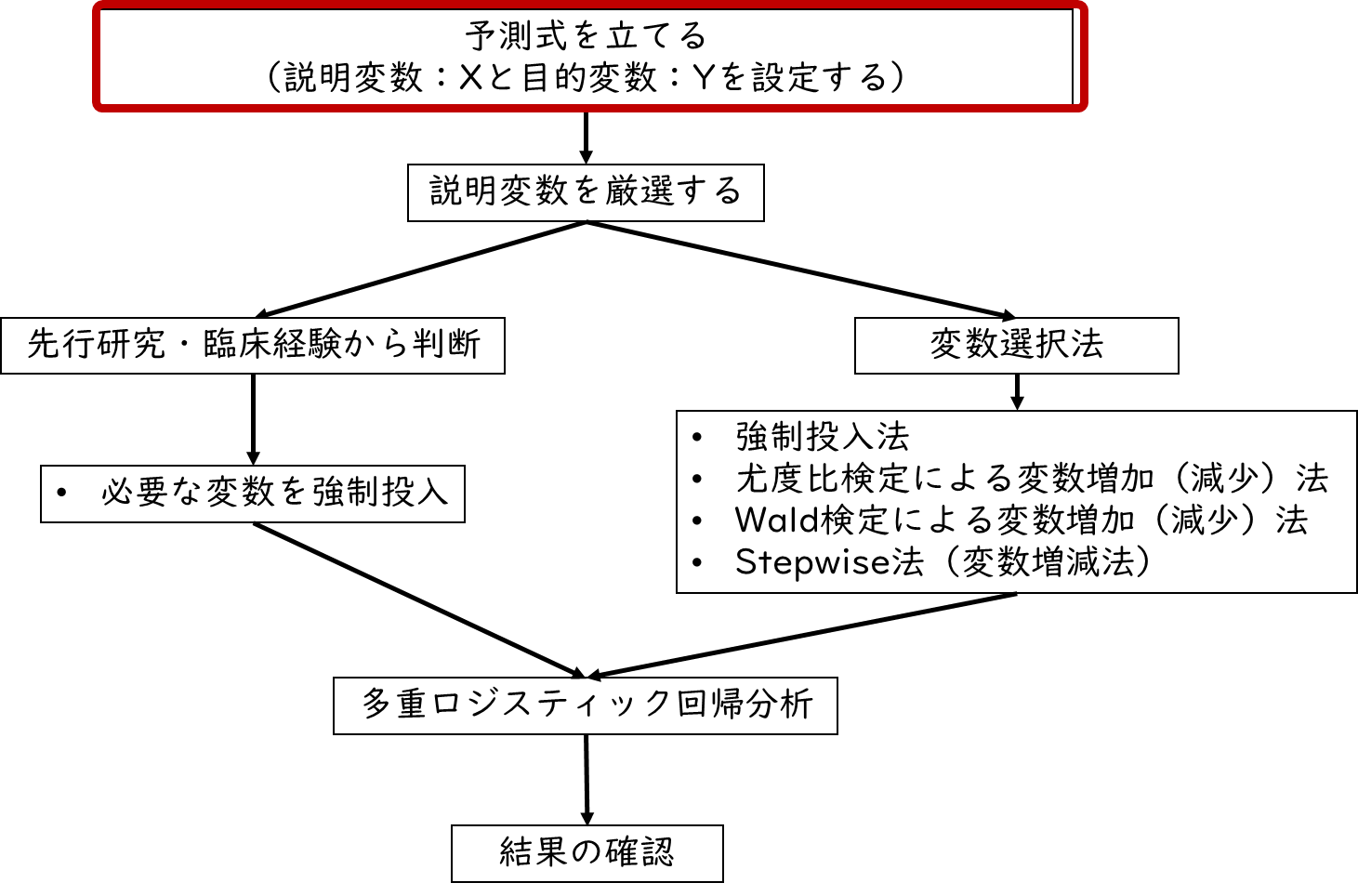
今回は、Sleeping(睡眠時間)とExercise(運動時間)がStiff shouler(肩こりの有無)に影響を与えるかを考えてみます。つまり説明変数が「Sleeping(睡眠時間)とExercise(運動時間)」、目的変数が「Stiff shouler(肩こりの有無)」です

交絡因子の検討
多重ロジスティック回帰分析では、仮説を予測する際に説明変数として交絡因子も含めることが重要です。交絡因子とは調査する変数以外で結果に影響を与える変数のことです。この変数を適切に調整しないと、研究結果の解釈に誤りが生じる可能性があります。
交絡因子は下記の3つの条件を含めるものと言われています。
- ➀結果に影響を与える
- ②原因との関連がある
- ③原因と結果の中間因子(原因と結果の間にある)ではない

交絡因子は簡単に言うと、事前の仮説以外にも影響のありそうな因子のことです。今回は交絡因子としてAge(年齢)とSex(性別)Department(部署)も説明変数に投入にします。

上記を踏まえて今回の予測式を図にすると、説明変数が「Sleeping(睡眠時間)、Exercise(運動時間)、Age(年齢)、Sex(性別)、Department(部署)」とし、これらの説明変数が、目的変数の「Stiff shouler(肩こりの有無)」に影響を与えるかどうかを検討します。
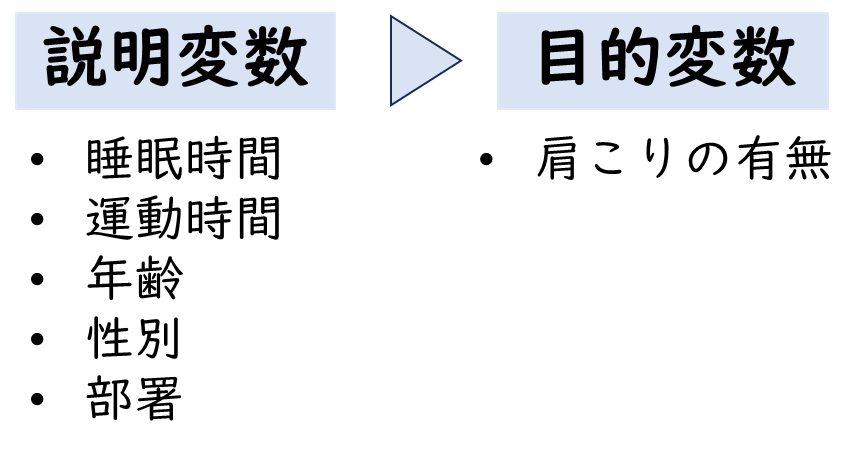
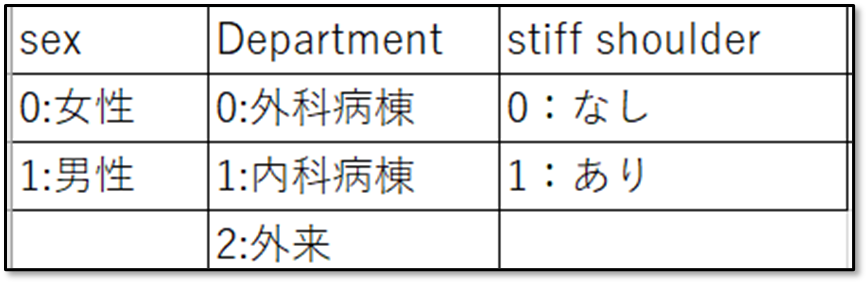
ダミー変数への対応は?
ちなみに、質的変数はダミー変数に変換して投入しています。今回のデータではSex(性別)とDepartment(部署)、Stiff shoulder(肩こりの有無)が質的変数なので、これらの変数を図のようにダミー変数に変換しています。

下記がダミー変数に変換した設定内容だよ。結果を見る時は、このように事前に設定した内容を見ながら確認するようにしよう。
②説明変数を選択する
予測式を立てることができたら、設定した説明変数がほんとに適切かを検討します。EZRでは解析と同時に変数選択法も選ぶので、解析する手順の中で、変数選択法についても一緒に解説していきます。
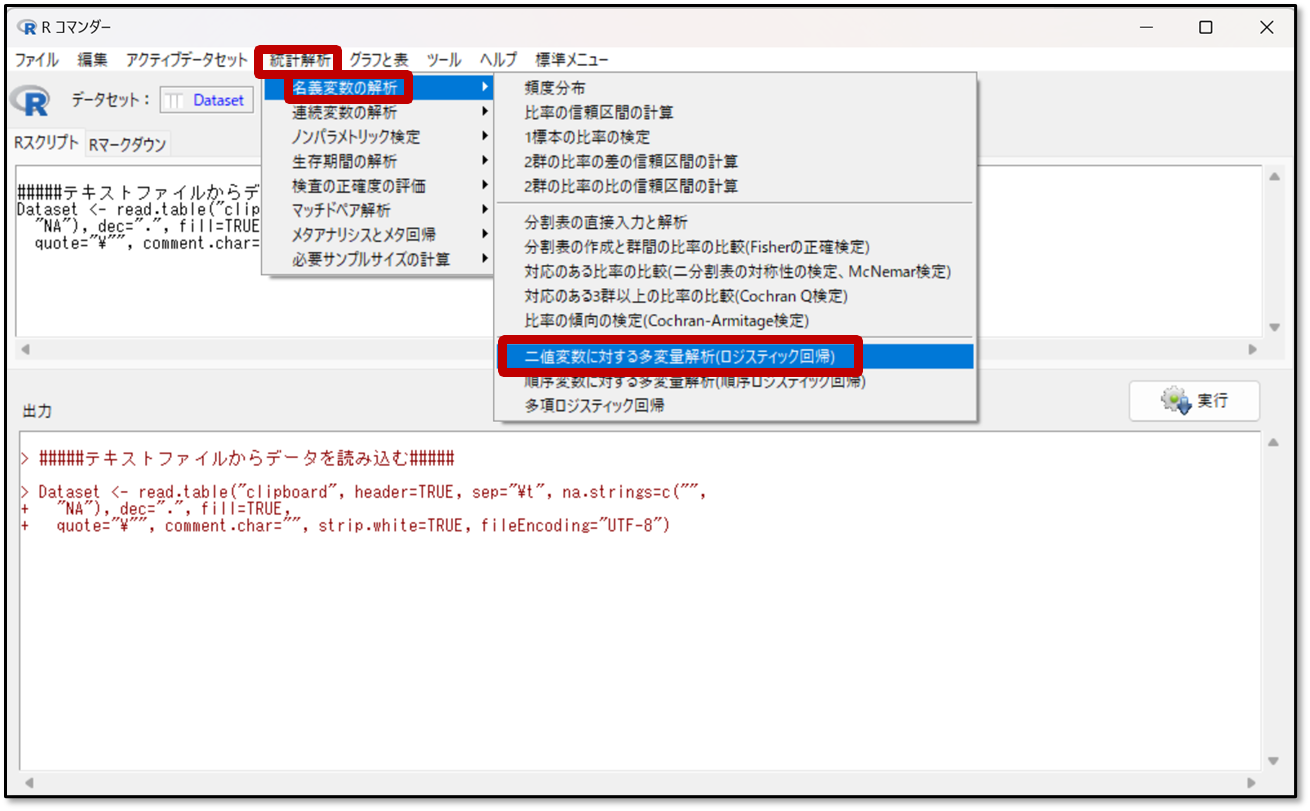
それでは多重ロジスティック回帰分析を実施していきましょう。EZRの操作画面で、「統計解析」→「名義変数の解析」→「二値変数に対する多変量解析(ロジスティック回帰)」を選択します。
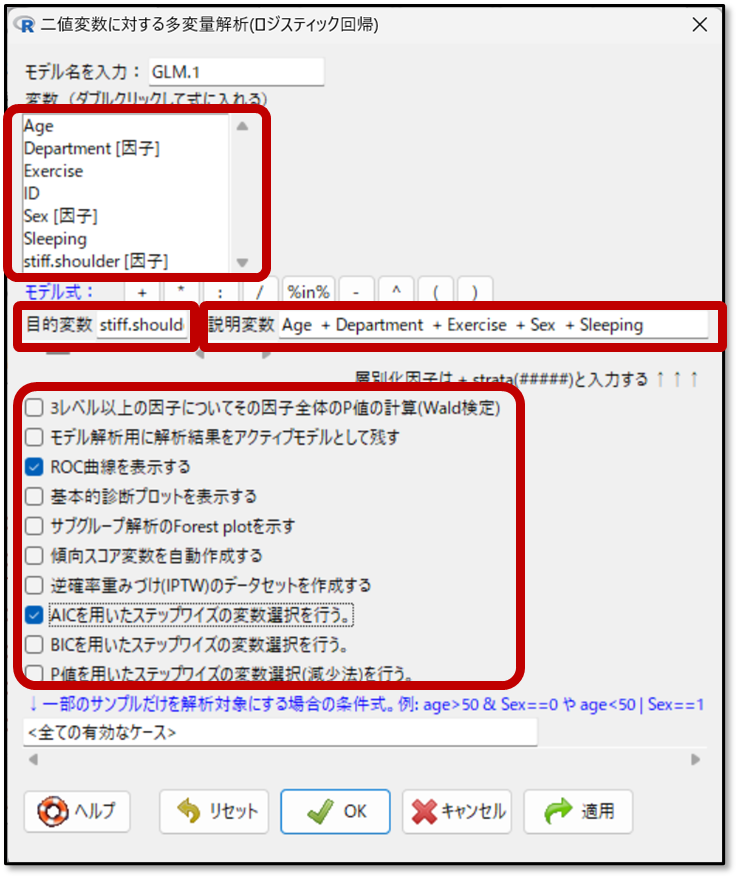
次の画面で、目的変数と説明変数を選択します。左上の変数をダブルクリックすると、目的変数から順番に入力されます。
このときに変数選択法も選びます。重回帰分析の時と同様に、とくべつな理由がなければ、AICを用いたステップワイズの変数選択にチェックを入れましょう。
AIC・BICとは?
AICとは(Akaike’s Information Criteria)の略で、BIC(ベイジアンBayesian Information Criteria)の略です。モデルの最適さを示す指標とだけ覚えておきましょう。
先に解析時の選択ですが、特別な理由がなければAICの使用を推奨します。BICでは選択される変数の数が少なくなる傾向にあります
ちなみに、多重ロジスティック回帰分析では、ROC曲線も確認したいため、ROC曲線を表示するにチェックを入れましょう。
あとは、OKを押して解析スタートです。
強制投入はしなくて良いの?
まずはステップワイズ法にて説明変数を絞った後に、自身が臨床的・先行研究的に重要だと思う変数が除かれてしまった場合に、強制投入を行いましょう。
強制投入法は、先ほどのEZRの操作画面で目的変数に影響を与えると思われる説明変数を全て選択し、変数選択法にチェックを入れずに解析を行えば完了です。変数選択法が行われないので自身の考える説明変数で解析することができます。
ステップワイズ法への批判
ステップワイズ法は便利な方法ですが批判的な意見もあるので覚えておきましょう。
ステップワイズ法を使用して変数を選択することについて、「少数の説明変数で予測可能なモデルを作成する場合」には有効な方法であるが、「因果関係を分析することが目的である場合」には適切ではないとの考え方があります。
「因果関係を分析することが目的である場合」は何が目的変数に影響するのかという仮説の設定が重要となります。そのため、統計的に仮説上必要な変数が除去されてしまうのは問題があります。看護研究で多いのは、因果関係を説明することが目的の研究です。
ですが基本を学ぶ上では、ステップワイズ法を選択するのも悪くないと思います。そのため基本的には、前述のようにステップワイズ法と強制投入法を組み合わせて行うことをおすすめします。
正規分布の確認はしなくて良いの?
多重ロジスティック回帰分析でも、重回帰分析と同様に正規分布の制約はありません。そのため正規分布を確認せずに解析を行うことができます。
多重ロジスティック回帰分析は制約が少なく使いやすい検定のため、多くの研究で使用されているよ!
③多重ロジスティック回帰分析の結果を確認する
それでは多重ロジスティック回帰分析を行った結果を見て行きましょう。
まずは変数選択の結果を確認
下記が今回の変数選択の結果です。まずはどのような予測式を立てて行った分析なのかを改めて確認しましょう。
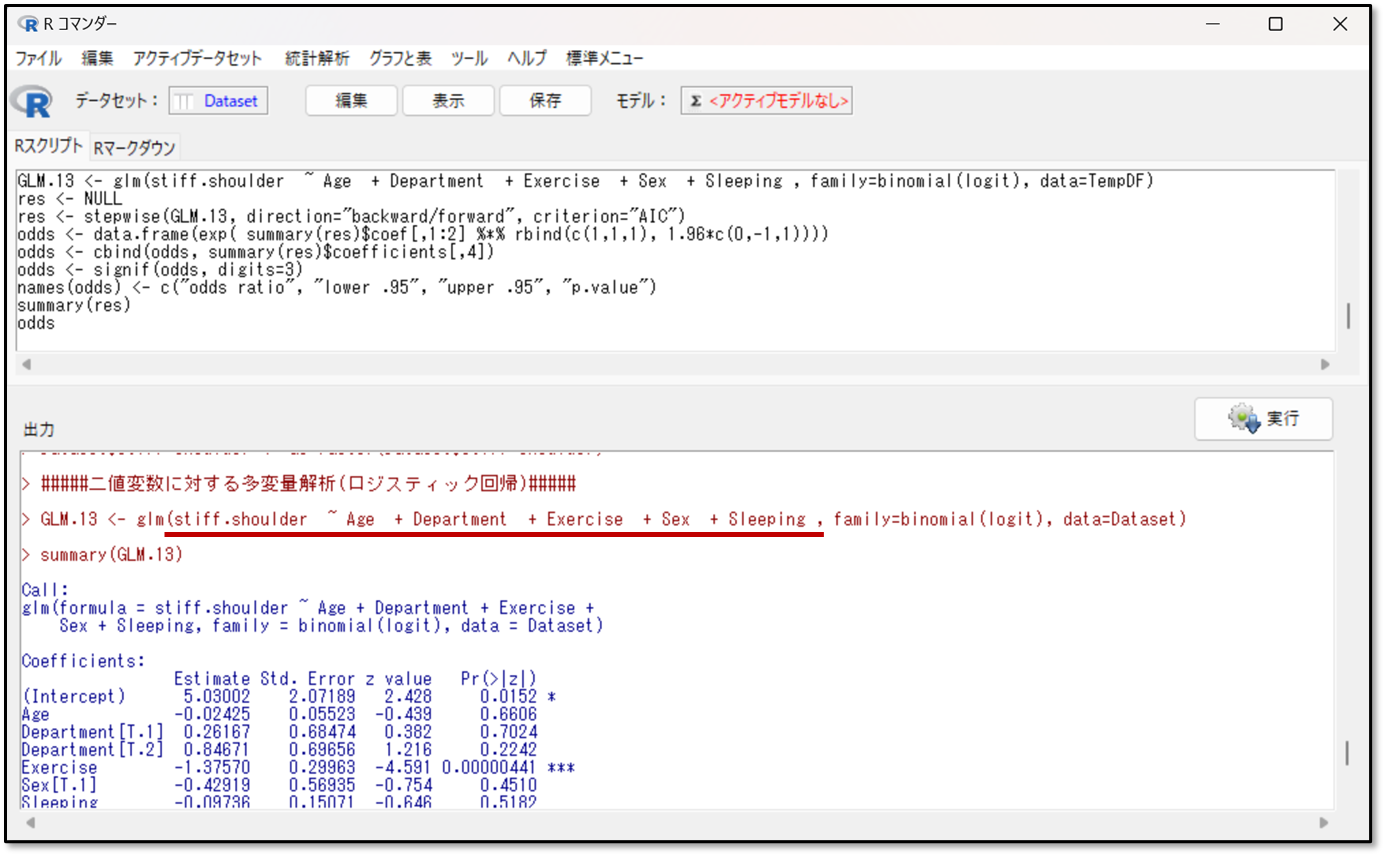
上記の出力画面の赤線の部分が、ステップワイズ法にて説明変数を選択する前の、自身で設定した予測式です。目的変数~波線、説明変数+説明変数+・・・と表示されます。今回の場合だと目的変数の肩こりの有無=年齢+部署+運動時間+性別+睡眠時間の予測式を立てて、解析を行ったことが分かります。
次に予測式の説明変数がどのように選択されたか確認します。下記に変数選択後の予測式が出力されています。
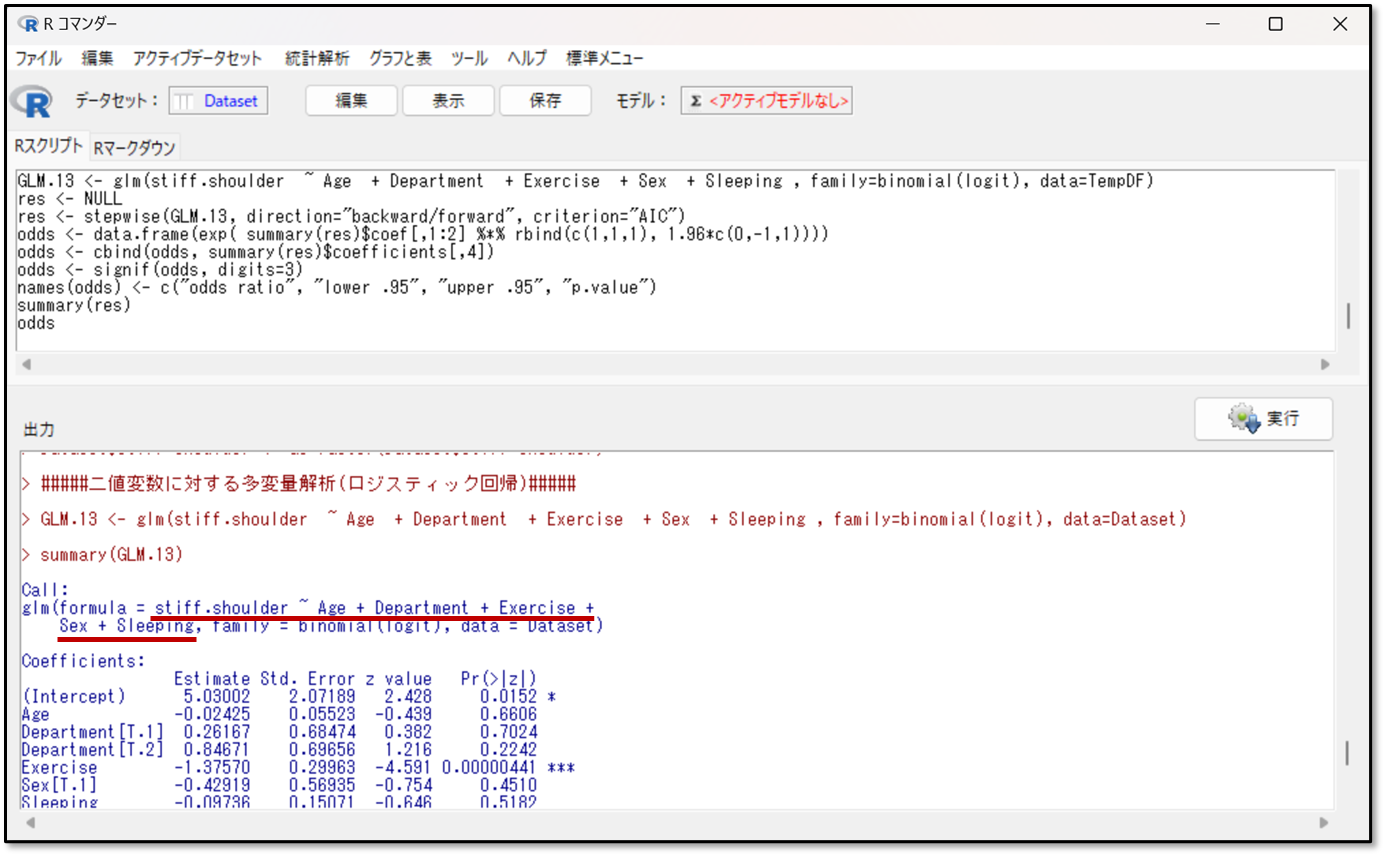
上記の赤線部分が、ステップワイズ法にて選択された説明変数が含まれた予測式です。さきほど同様に、目的変数~説明変数+説明変数+・・・と続きます。つまりY=X+X+・・・という予測式のことです。
今回の変数選択法により導かれた予測式は、最初に設定したものから変更はありませんでした。そのため説明変数は最初に設定したものから削られなかったということです。
もしこの段階で、仮説設定上、重要な変数が削られてしまった場合は、変数選択法にて選ばれた説明変数と、重要だと考えている変数を含めた上で強制投入法を行いましょう。
多重ロジスティック回帰分析の結果を確認
多重ロジスティック回帰分析の結果は下記について確認します。
それぞれ詳しく解説するよ
➀予測式が役に立つかどうか(尤度比検定の結果)
予測式が役に立つかは尤度比検定(モデルχ二乗検定)の結果を確認します。この結果はモデル適合度、つまりモデル全体の有用性を示します。
モデルχ二乗検定の結果がp<0.05の場合、この予測式が、目的変数に対して説明変数が有意に影響するモデルであると判断します。つまり、予測式が有用なモデル(適合の良いモデル)であることを示しています。もしこの結果がp≧0.05であれば、今回の予測式は役に立たないので、この時点で解析は終了となります。
下記が今回の出力結果です。
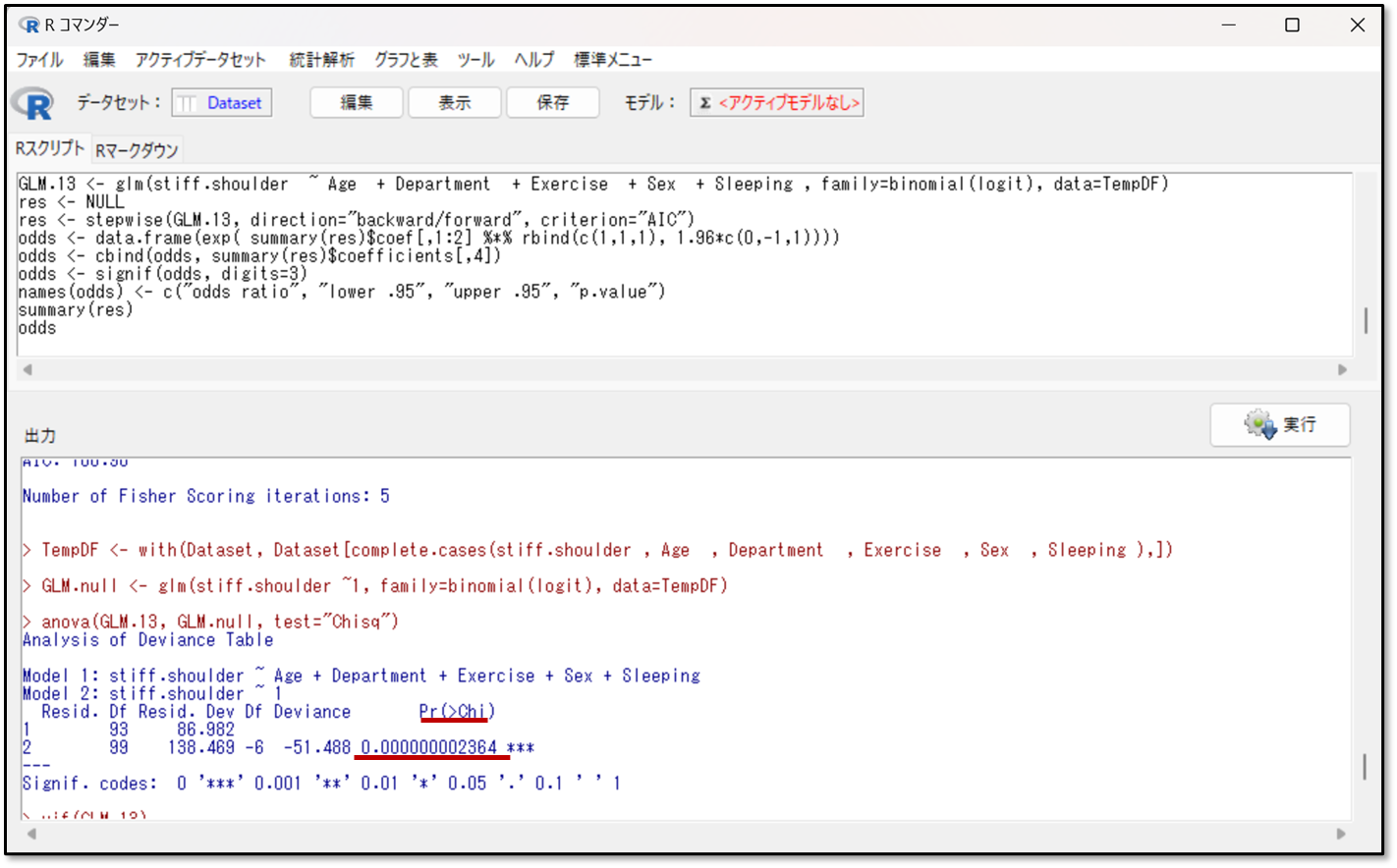
Pr(>Chi) と記載されている部分がp値です。P<0.05であれば有用なモデルと解釈します。今回は、0.000000000000002364なので、有用なモデルであることが分かります。
②回帰式の予測精度(Hosmer-Lemeshow検定)
次に回帰式の予測精度を確認しましょう。予測精度の確認方法は様々ですが、Hosmer-Lemeshow(ホスマーレメショウ)検定の結果を確認することがほとんどです。
Hosmer-Lemeshow(ホスマーレメショウ)検定とは、回帰式の適合性(当てはまりのよさ)を分析する検定です。実測値(実際に測定された値)と予測値(回帰式により算出された値)を比較することで分析を行います。
適合性とは予測精度のことで、重回帰分析における決定係数R²(予測精度)のようなものです。p≧0.05の時に、回帰式が良く適合している(精度が高い)と判断します。
p<0.05じゃないから注意してね
Hosmer-Lemeshow(ホスマーレメショウ)検定をEZRにて実施する際は、パッケージの追加が必要となるため下記で詳しく解説します。
先に今回の出力結果を示します。
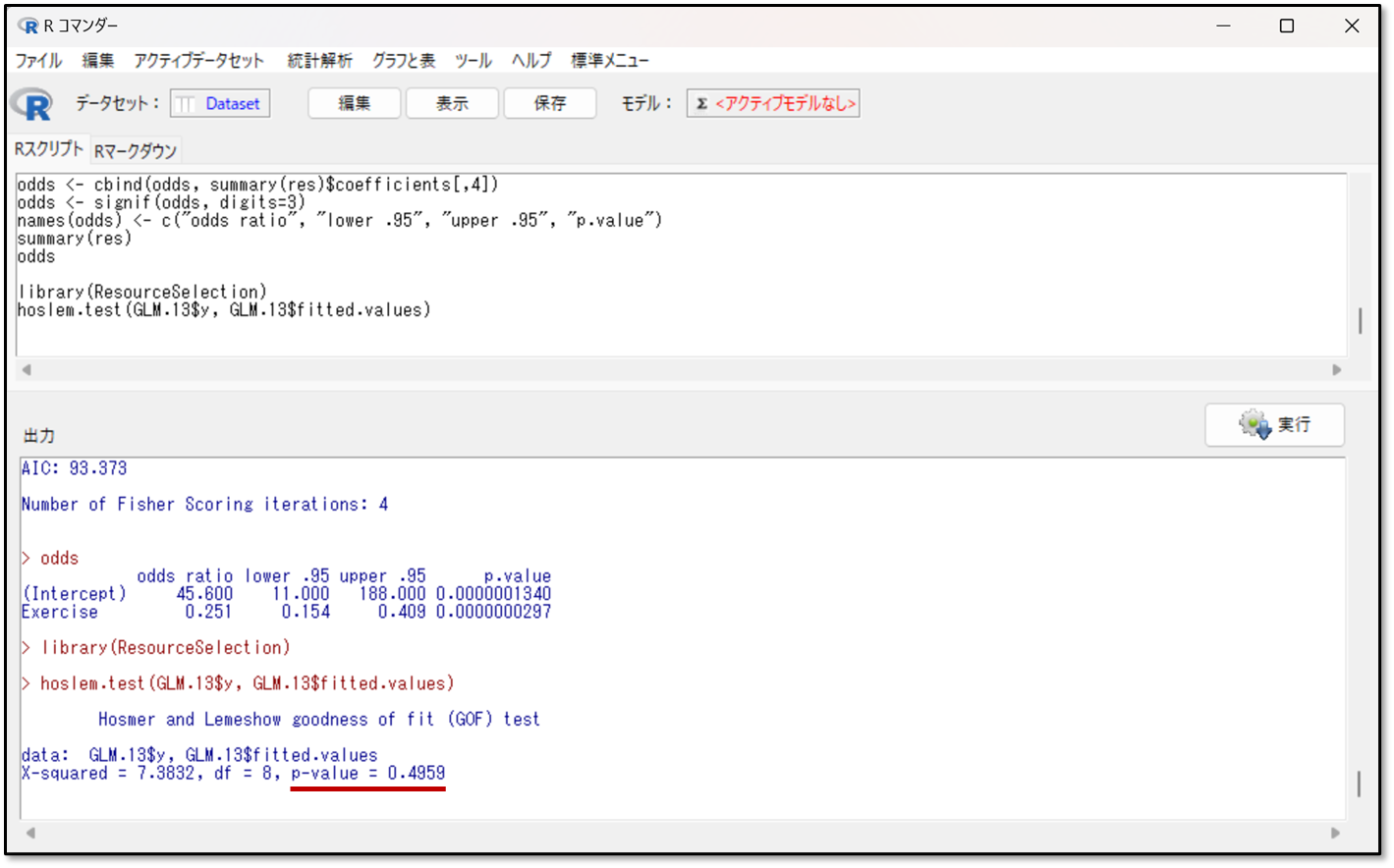
今回は、P=0.4959で、pが0.05以上(p≧0.05)のため、Hosmer-Lemeshow(ホスマーレメショウ)検定上は、あまり予測性能が高くないという判断になります
EZRでHosmer-Lemeshow検定を行う方法
前述の通り、EZRにてHosmer-Lemeshow(ホスマーレメショウ)検定を実施する際は、パッケージの追加が必要となります。
EZRを起動すると、通常の操作画面であるRコマンダーとは別に、Rコンソールという画面が表示されていると思います。その画面からパッケージを追加していきます。
まずは「パッケージ」→「CRAN ミラーサイトの設定」を選択し「JAPAN」を選択しOKを押します。
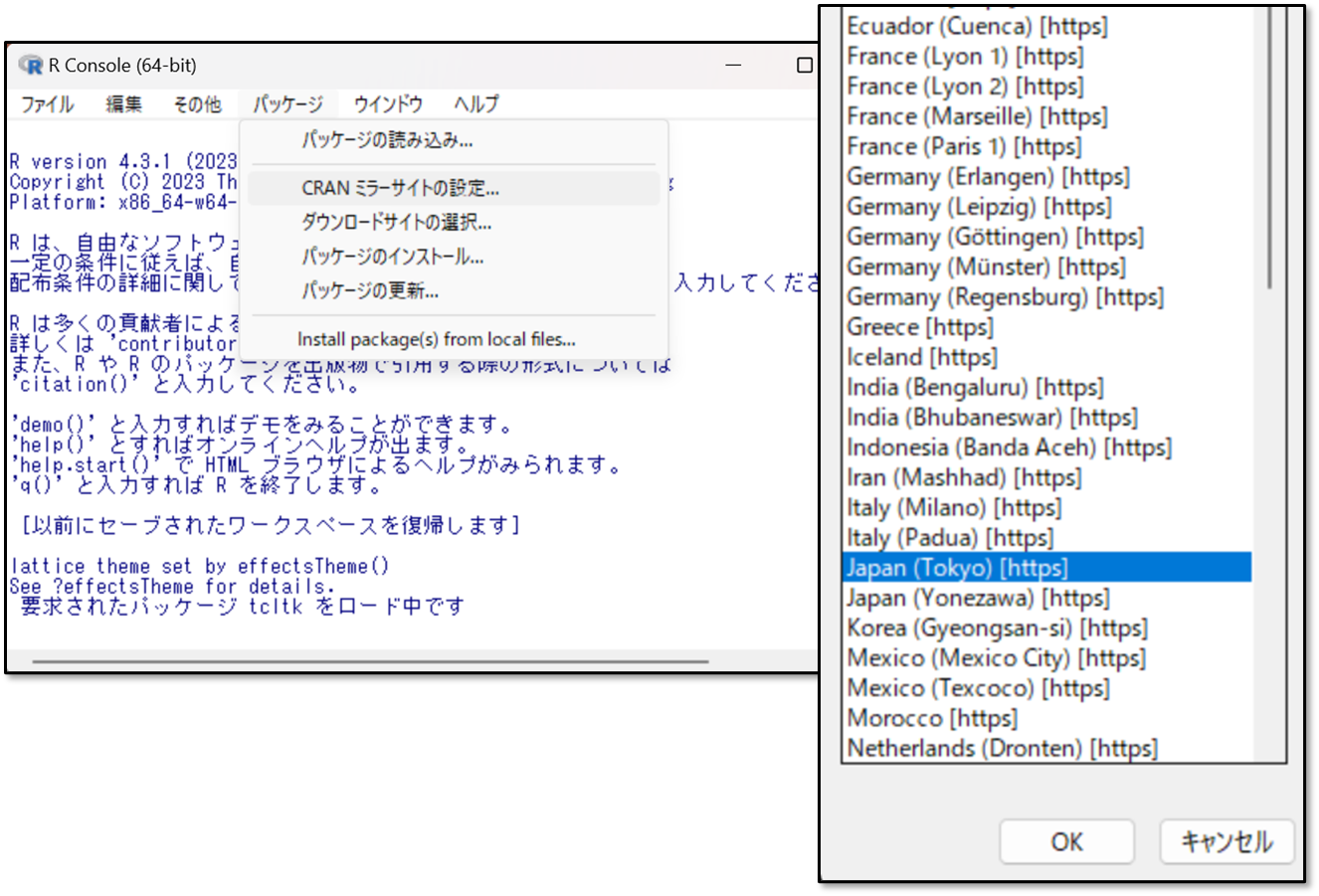
その後で、「パッケージ」→「パッケージのインストール」を選択した上で、「ResourceSelection(リソースセレクション)」というものを探して選択し、OKを押します。これでパッケージのインストールは完了です。
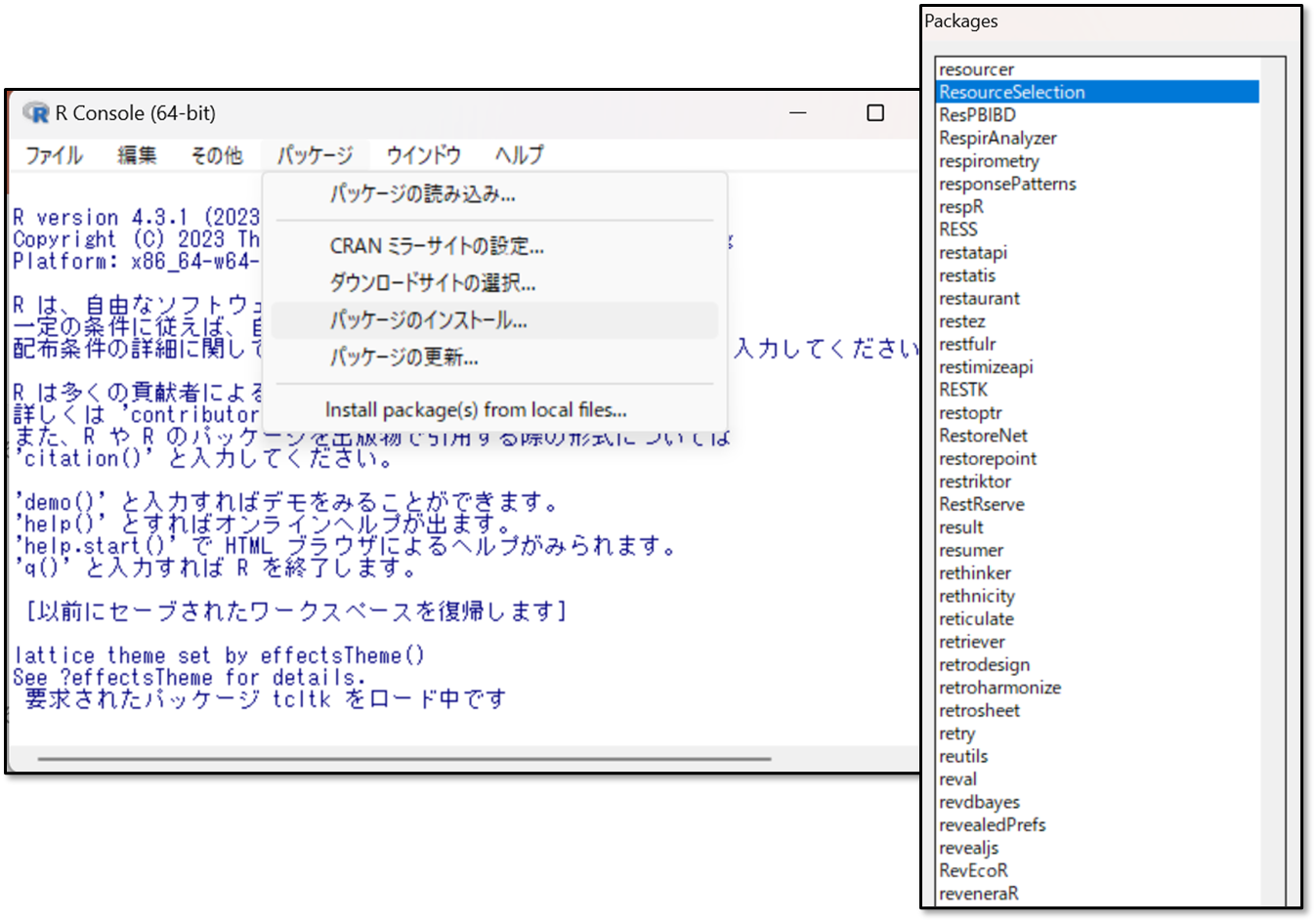
続いて、インストールしたパッケージを呼び出して実行する作業を行います。すでに解析が終わっている段階からの作業として解説します。
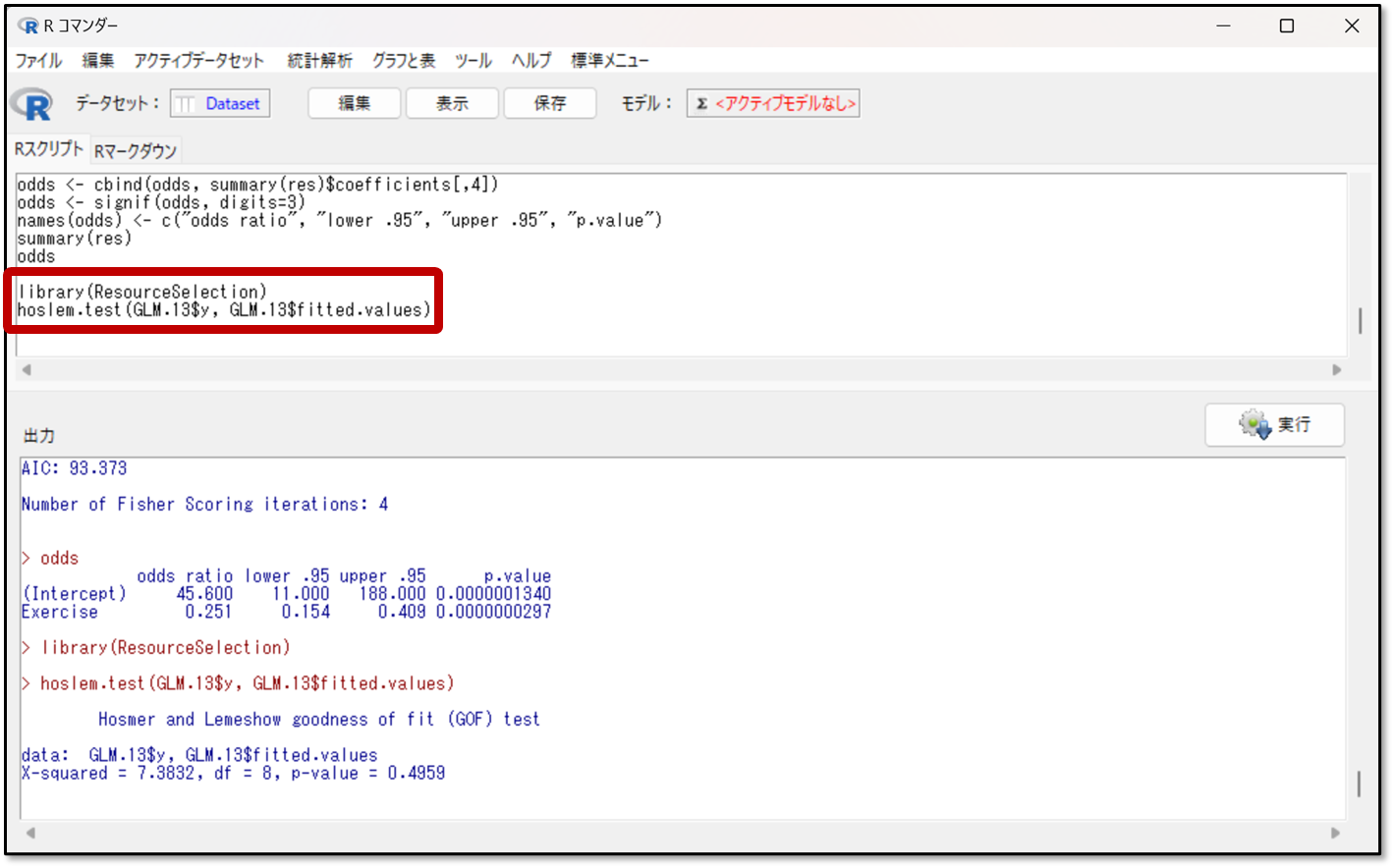
EZRの操作画面の上部にあるRスクリプトの画面に、スライドにあるlibrary(ResourceSelection)から始まるコードを入力します。
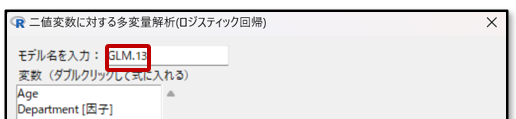
モデル名とは、解析条件を入力した操作画面に記載のモデル名です。
Rスクリプトへの入力が完了したら、選択して実行を押します。
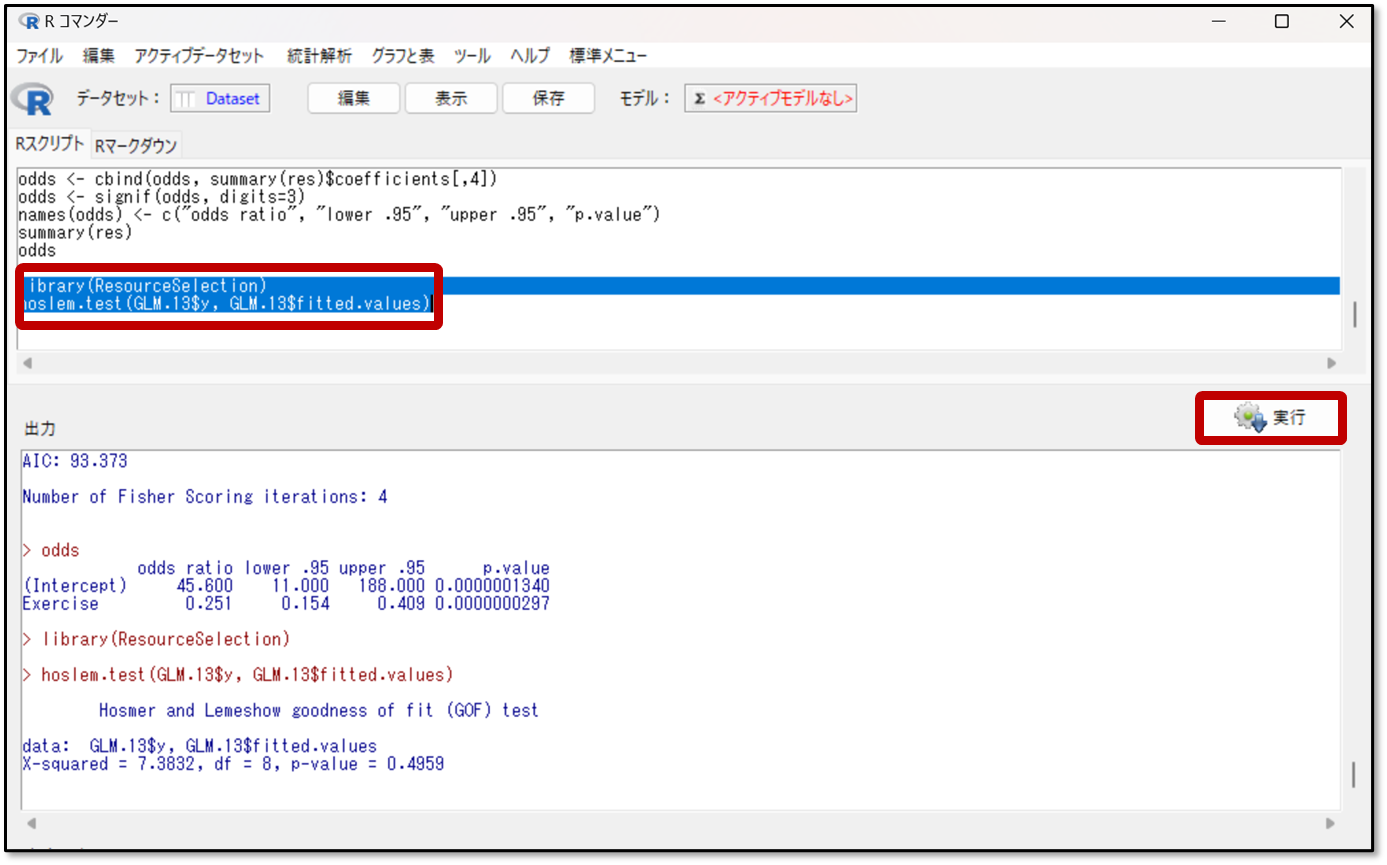
実行を押すと出力画面に、前述のHosmer-Lemeshow(ホスマーレメショウ)検定の結果が表示されます。
②回帰式の予測精度(判別的中率)
判別的中率が算出される統計ソフトと、算出されない統計ソフトがあります。そのため、算出されるソフトを使用している場合は確認しましょう。
看護研究でも多く使われているSPSSでは算出されるけど、当ブログで使用しているEZRも判別的中率は算出されないよ。
判別的中率とは、実測した値と予測した結果が一致した割合のことです。75~80%以上の判別的中率で予測精度が高いと判断します。
判別的中率を考える際の例
判別的中率は、正しく正解できた割り合いです。そのため、下記の例だと、全体40人のうち正しく予測(つまり疾患ありを疾患あり、疾患なしを疾患なし)できているのが33人なので、33÷40×100で82.5%となります。つまり、予測精度が高いと判断できます

②回帰式の予測精度(ROC曲線)
ROC曲線とは、一般的に検査の診断能の評価や、最適なカットオフ値の選定などに用いられる分析方法です。カットオフ値とは、検査や測定結果の陽性・陰性を識別する数値のことです。
先に一般的なROC曲線の概要について解説するね。
検査の診断能を分析する際のROC曲線の基準としては、ROC曲線の下部分の面積(AUC: Area Under Curve) が、0.5~1.0 までの範囲をとり、1.0 に近づくほど診断能が高いと解釈します。下記が検査の診断能の分析でROC曲線を使用している例です。
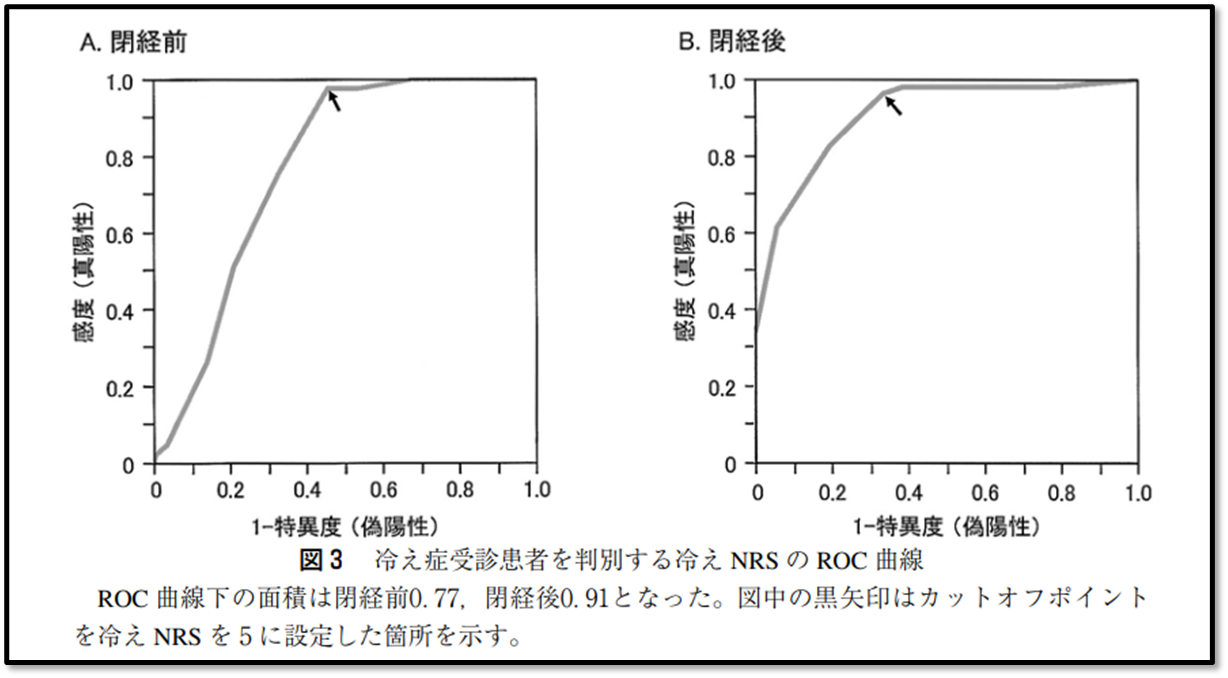
多重ロジスティック回帰分析の解説に戻ります。多重ロジスティック回帰分析の際に算出される ROC曲線は、2値の目的変数を適切に予測できるか(予測精度)を確認するのに使用されます。
検査の診断能を分析する際と同様の解釈で、 0.5~1.0 までの範囲をとるROC曲線下面積 のAUC(Area Under Curve) が1.0 に近づくほど、回帰式の予測確度が高いと解釈します。
下記が今回の出力結果です。解析前の操作画面に、ROC曲線を表示するにチェックを入れると、出力結果として下記のようなROC曲線が出力されます。
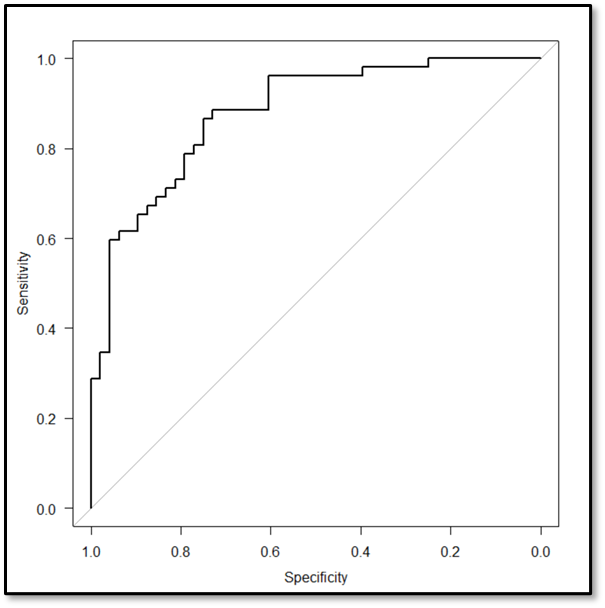
またROC曲線についての情報は出力結果の赤枠部分にも表示されています。
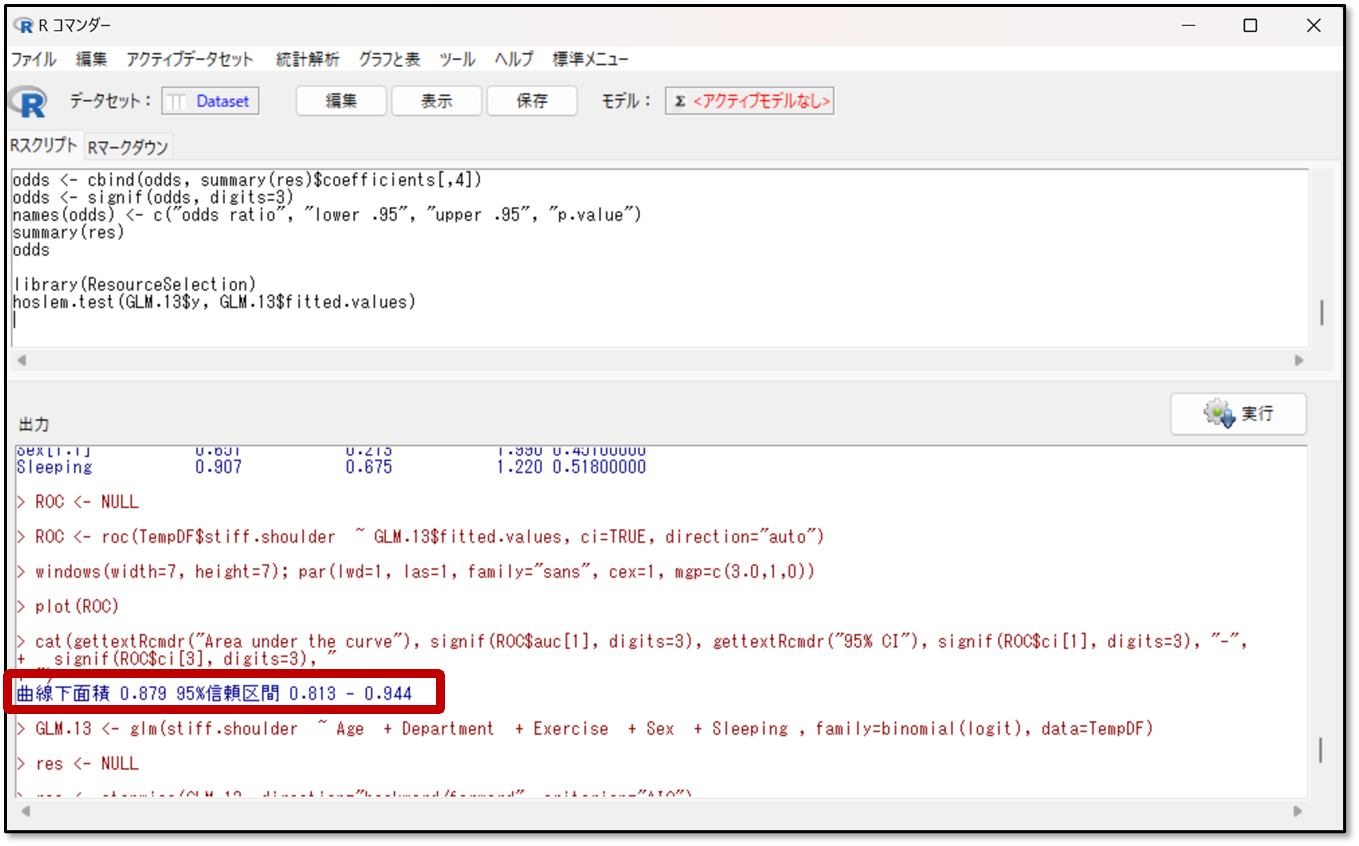
今回は曲線下面積が0.879で95%信頼区間の下限も0.813なので、高い予測精度であると判断します。
回帰式の予測精度は、Hosmer-Lemeshow検定やROC曲線などの複数の指標から総合的に判断しよう。
③多重共線性(VIF)
多重共線性とは説明変数と説明変数の間の関係の強さのことで、複数の説明変数間に高い相関(強い関係)がある場合に適切な分析結果が出ない状況のことです。
分散拡大要因(VIF)が算出できる場合は、VIFにより多重共線性の有無を確認します。基準はVIFが5以上で多重共線性の可能性ありと判断し、VIFが10以上で多重共線性の可能性がかなり高いと判断します。多重共線性がある場合は、VIFが高い変数を除去して再度分析を行います。
VIFが算出できない場合は、各説明変数間の相関係数を確認して、相関係数が0.9以上であった場合に多重共線性があると判定するよ。この場合は、相関係数が0.9以上の変数を除去して再度分析を実施しよう。
下記が今回の出力結果です。
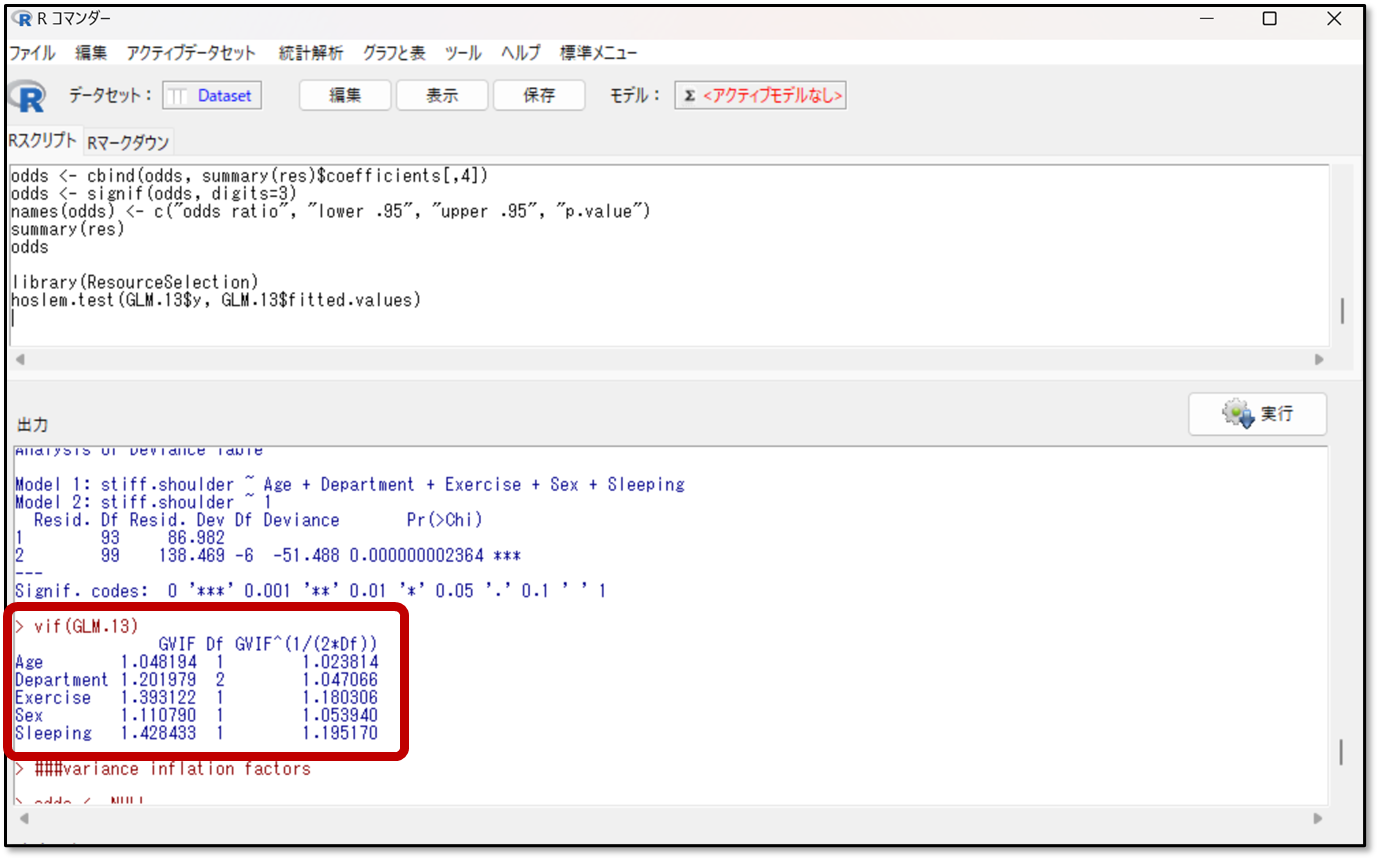
上記のvifと書かれたところを確認します。今回は、全ての変数が1から1.5の値なので、多重共線性の可能性は低いと判断します。
④説明変数の影響(影響の大きさ:オッズ比)
多重ロジスティック回帰分析の説明変数の影響の大きさはオッズ比にて判断します。オッズ比とは、ある要因(説明変数)とある結果(目的変数)の関係性を表す指標で、要因が無い時と比較して要因があった時には、何倍で結果が起こりやすいかを表しています。
オッズ比の数値は0~無限の値を取ります。オッズ比が1の時は全く影響しないと考えます。またオッズ比が1より大きくなるほど、1より小さくなるほど要因は結果に関係があると判断します。
オッズ比は、説明変数が1増加した時に、目的変数が何倍起こりやすくなるかを表した指標だから、オッズ比が4だから4倍のリスクがあるという解釈は間違っているよ。解釈が難しいから例を挙げながら解説するね。
例えば下記の図のように、説明変数①が「喫煙年数(年単位:量的変数)」、説明変数②が「性別(男・女:質的変数)」、目的変数が「疾患の有無」の場合で考えます。その際に説明変数①の「喫煙年数」のオッズ比が2.8、説明変数②の「性別」のオッズ比が1.4という結果が算出されたと仮定します。

まずは量的な説明変数のオッズ比の解釈から解説します。説明変数①の「喫煙年数」は年単位で、喫煙歴21,22,23….年などになります。オッズ比は「説明変数が1増えた時に、目的変数が何倍起きやすいか」のため、オッズ比2.8とは説明変数①の「喫煙年数」が1年増えると疾患が起きる確率が2.8倍になるという解釈です。また喫煙年数が3年増えた時は、説明変数が3増えるので、2.8³となり、疾患が起きる可能性が21.952倍となります。
次に質的な説明変数のオッズ比の解釈について解説します。質的変数は「0・1」のダミーデータに変換しています。そのため、説明変数が1だけ増加するということは「0→1」の変化ということです。つまり「男→女」「あり→なし」の変化です。上記の例だと性別のオッズ比は1.4です。ダミーデータの変換を男(0)・女(1)とすると、男性と比較して女性(0→1)は1.4倍疾患になりやすいと解釈します。
オッズ比が1以下の解釈
オッズ比が1以下の場合は逆数にして「起こりにくさ」を考えましょう。オッズ比は0~∞の値を取るため、当然1以下になることもあります。
例えば説明変数「喫煙年数(年単位)」のオッズ比が0.8だとすると、喫煙が1年増加すると「0.8倍で疾患になりやすい」と解釈します。しかし、0.8倍と言われても分かりづらいため、0.8の逆数(1÷0.8)を取り「1.25倍で疾患になりにくい」と解釈します。
オッズ比の注意点
ダミーデータの「0・1」の変換は研究者が決めます。そのためダミーデータは、どちらが0でどちらが1と設定していたかを忘れずに確認するようにしましょう。0と1を反対に解釈すると、逆数の結果となってしまいます。
例えば、ダミーデータを男(0)・女(1)だと解釈していが、実は男(1)・女(0)だった場合を考えます。上記の例だと、女性だと1.4倍で疾患になりやすいと解釈しましたが、実は反対で1÷1.4(逆数)で女性だと0.71倍で疾患になりやすい(1.4倍で疾患になりにくい)という、まったく違う解釈になるので注意しましょう。
それでは今回の出力結果を見てみましょう。
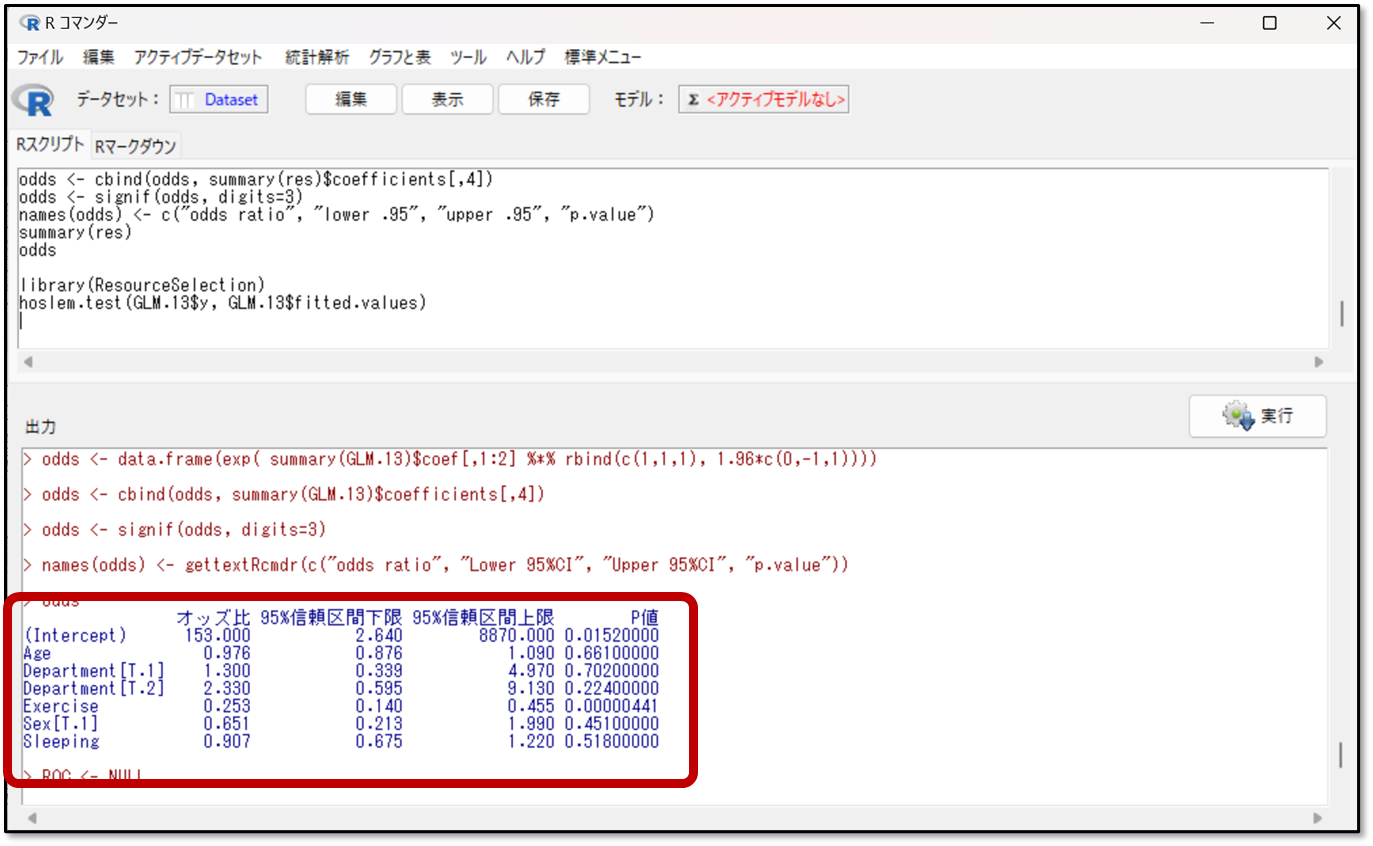
出力結果の赤枠の部分を確認します。例えば量的な説明変数のAge(年齢)であれば、オッズ比が0.976なので、年齢が1年増えれば、肩こりが起きる(0→1)可能性が0.976倍となると解釈します(逆数で1.024倍で肩こりが起こりにくい)。
また質的変数に関してはSex(性別)であれば、オッズ比が0.651なので、性別が0→1(女性→男性)で肩こりが起こる(0→1) が0.651倍になると解釈します(逆数で1.536倍で肩こりが起こりにくい)。
下記がダミー変数に変換した設定内容だよ。
④説明変数の影響(有意に影響があるか:オッズ比の95%信頼区間)
多重ロジスティック回帰分析の説明変数が有意に目的変数に影響があるかどうかは、オッズ比の95%信頼区間で判断します。
95%信頼区間とは?
95%信頼区間とは真の値を区間で推定するもので区間推定と言われます。統計は母集団の数値(真の値)を推定する作業です。その真の値が95%の確率で入る範囲(区間)を表したものが95%信頼区間です。
95%の確率とは、複数の研究者が同じ研究をしたら95%の研究で、このくらいの範囲の値を取るだろうということです。
95%信頼区間について詳しく知りたい方は【95%信頼区間とは?】看護師必見「大事なのはp値だけじゃないよ」を参照してください。
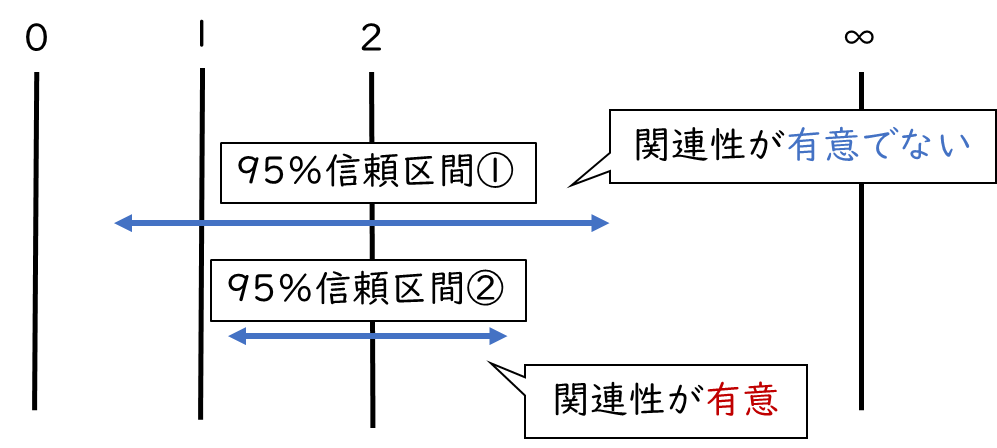
オッズ比の95%信頼区間では、オッズ比の区間推定に加えて「オッズ比に有意な関連がある(説明変数が目的変数に有意に影響する)」かどうかを評価することができます。オッズ比の95%信頼区間の下限が1より大きい(オッズ比の95%信頼区間:1.5ー3.5など)のとき、統計学的に「オッズ比に有意な関連がある(説明変数が目的変数に有意に影響する)」と解釈します。
オッズ比の95%信頼区間の下限が1より大きいということは、95%の確率でオッズ比が1を上回ると推定されます。この場合は「オッズ比に有意な関連がある」可能性が95%以上ということです。
例えば下記の図で見ると、➀であれば有意な関連がないと判断し、②であれば有意な関連があると判断します。
ちなみにオッズ比の95%信頼区間は「オッズ比の精度」も判定できます。オッズ比の95%信頼区間の幅が狭いほど精度が高くなります。
オッズ比の精度を確認する計算は簡単で、オッズ比の「95%信頼区間の下限値÷上限値」です。基準は下記の表の通りです。
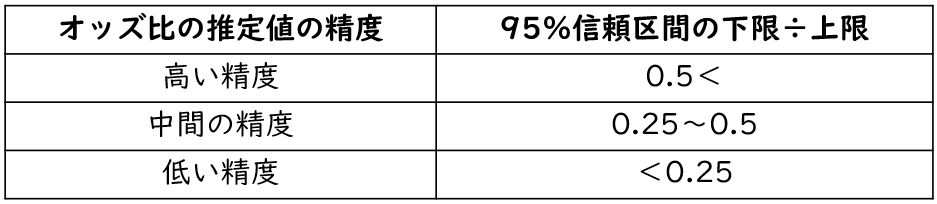
例えばオッズ比の95%信頼区間が1.2-3.8だとすると、1.2÷3.8=0.31となり、オッズ比は中程度の精度があると判断します。
オッズ比の有意性も、オッズ比の精度も、あくまで基準だから判断の1つとして捉えておくことが大切だよ。
それでは今回の結果を見てみましょう。
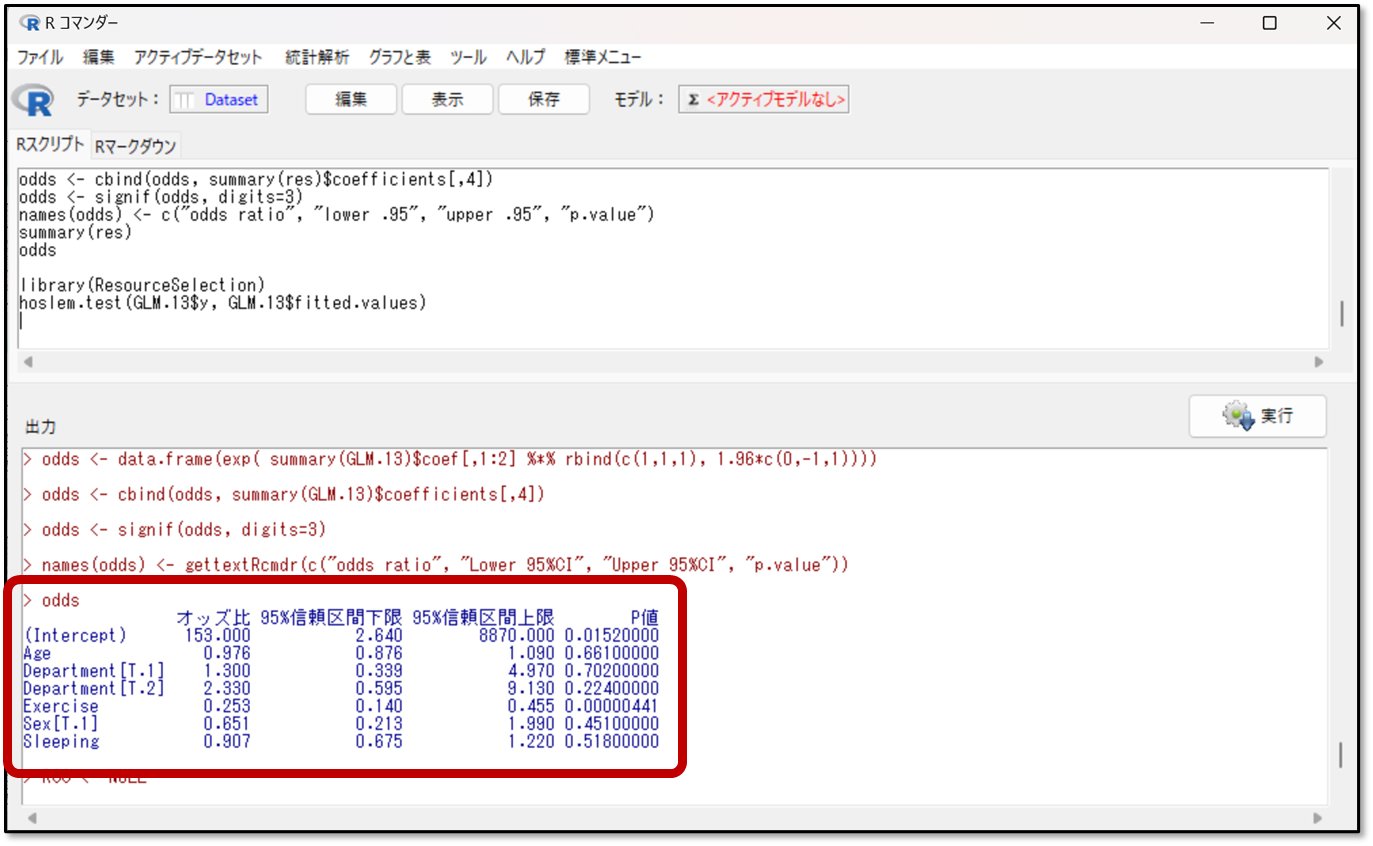
オッズ比の95 %信頼区間は、赤枠部分の95%信頼区間と書かれたところを確認します。今回の結果であれば、例えば、Sleeping(睡眠時間)であればオッズ比の下限が0.675、1より小さいので、この説明変数は、統計学的に有意に目的変数に影響しているとは言えないと判断します。
また、オッズ比の精度も見てみます。同様にSleeping(睡眠時間)のオッズ比を見ると、95%信頼区間が下限が0.675、上限が1.220なので、下限÷上限で計算すると、結果は0.55となります。つまり、オッズ比の精度は高いと判断します。
オッズ比が有意に影響がないからと言って、まったく目的変数に影響がないわけでないので注意しましょう。オッズ比の値(95%信頼区間の区間推定も含め)を確認し、臨床経験と合わせながら説明変数の影響を評価をすることが大切です。
まとめ
多重ロジスティック回帰分析は、看護研究において目的変数が2値の場合に複数の説明変数が与える影響を解明する有用なツールです。適切なモデル構築と解釈により、因果関係の理解を深め、効果的な介入を導き出すことが可能になります。この記事が多重ロジスティック回帰分析の理解と実践の助けとなることを願います。
この記事を通じて基本的な理解を深め、実際のデータ解析に活かしていただければ幸いです!
今回は多重ロジスティック回帰分析を実際に行う方法を解説しました。多重ロジスティック回帰分析の概要について詳しく知りたい方は【多重ロジスティック回帰分析:概要編】看護研究の疑問を解決「因果関係を調査しよう」を参照してください。

コメント