








Last Updated on 2026年4月9日 by カメさん

こんにちは!看護師のカメさん(@49_kame)です。
この記事は10分程度で読めます。
今回は統計解析ソフトEZRを使用して実際に重回帰分析を行う方法を解説します。
重回帰分析は、看護研究において、複雑なデータの中から価値ある情報を抽出するための重要なツールとなります。この統計手法を用いることで、複数の因子が患者の健康状態や治療結果にどのように影響しているかを明確にすることができます。看護研究における重回帰分析の適用は、より科学的で効果的な看護介入の開発へと繋がるため、非常に価値が高いと言えるでしょう。
この記事では、重回帰分析の基本を解説するとともに、デモデータを使用して実際に重回帰分析を行う手順を一歩一歩、初学者でも理解できるように丁寧に解説していきます。
この記事を通じて、看護研究における統計分析の基礎知識を身につけ、実際の研究でこれらの手法を効果的に活用するための一歩を踏み出すことができれば幸いです!
このブログでは統計解析ソフトしてEZRを使用しています。EZRは無料かつ精度も高い統計解析ソフトであるためおすすめです。EZRの概要とインストール方法については【EZRの概要とインストール方法】看護研究を変える!EZRで効率的な統計解析を参照してください。
はじめに
まずは重回帰分析を行うための基礎知識から解説します。先に具体的な手順を知りたい方は、「重回帰分析の検定手順」から参照してください。
重回帰分析の概要を知りたい方は【重回帰分析:概要編】看護研究の疑問を解決「因果関係を調査しよう」を参照してください。
説明変数と目的変数
重回帰分析を理解する上で、まずは説明変数と目的変数を理解することが重要となるため、先に解説します。そもそも変数とは数量のことです。数学でいうXとかYのことです。医療統計で良く出てくる変数は体重や身長、テストの得点などです。
まず説明変数について解説します。説明変数とは因果関係の中で原因になる変数のことです。独立変数とも呼ばれます。
説明変数は、「目的変数を説明する変数」なので、「説明」変数と呼ばれるよ
続いて目的変数について解説します。目的変数とは物事の結果になる変数です。従属変数とも呼ばれます。
目的変数は、「説明変数から予測したい結果、つまり目的のこと」だから「目的」変数と呼ばれるよ
例えば、下記のように食事量が原因で体重が変化するかどうかを検討したい場合は、説明変数が食事量で、目的変数が体重になります。このように、研究では説明変数が本当に目的変数を説明しているかを検討します。

まとめると、説明変数は目的変数の変動を説明するために使用される変数です。そして、目的変数は分析の結果予測したいまたは説明したい変数です。
重回帰分析では、複数の説明変数を用いて目的変数の変動を説明するよ
重回帰分析とは?
まずは回帰分析について簡単に解説します。回帰分析とは説明変数から、1つの目的変数を予測する手法です。そして、重回帰分析とは説明変数が複数あるものです
回帰分析の大きな特徴は、下記のように説明変数と目的変数の関係を分析することにより、因果関係を分析できることです。因果関係の分析を理解するためには回帰式について理解する必要があります。後程解説します。

回帰分析と重回帰分析の違い
回帰分析は1つの説明変数と1つの目的変数の関係を分析しますが、重回帰分析は複数の説明変数を考慮します。これにより、現実の複雑な問題に対してより詳細な分析が可能になります。
回帰式とは?
回帰分析では、回帰式を求めることで因果関係を分析することができます。回帰式とはy=a+bxの式のことです。これは原因である説明変数と結果である目的変数の因果関係を表す関係式のことです。
回帰分析はy=a+bx で表現します。そして重回帰分析はy=a+b₁x₁+b₂x₂・・・です。重回帰分析は説明変数が複数あるので、説明変数xを増やして表現します。
下記の図のようにYが目的変数、aが定数、bが回帰係数と呼ばれるもので、xが説明変数です。回帰係数とは説明変数の影響の大きさです。
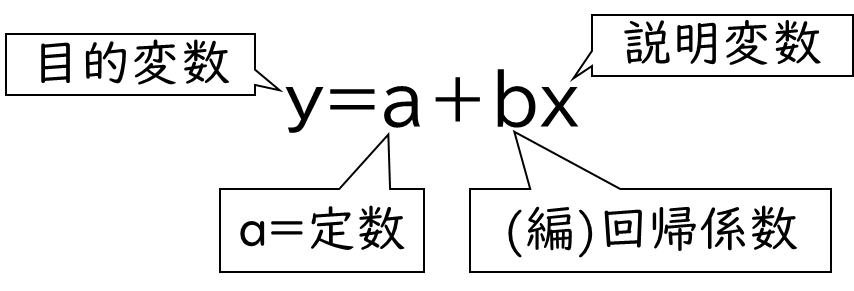
回帰係数については検定手順を解説する際に詳しく解説するね
回帰式は図としても表現され回帰直線と呼ばれます。回帰直線とは散布図(測定値を点で記載した図)の真ん中に引かれている線のことです。

※重回帰分析と多重ロジスティック回帰分析の違い
重回帰分析と同様に関係性を推測する検定方法に多重ロジスティック回帰分析があります。看護研究で多用されているので耳馴染があると思います。多重ロジスティック回帰分析と重回帰分析大きな違いは目的変数です。
重回帰分析では、結果である目的変数(y)は連続変数であることが原則です。そして多重ロジスティック回帰分析では目的変数(y)が 「あり or なし」のような2値をとります。
連続変数とは、重さや温度などのように連続した値をとるもので「間に無限に値がある数値」だよ。そのため、連続変数は計算が可能な変数とも言えるね。
重回帰分析の基本的手順
重回帰分析の基本手順を下記に示します。
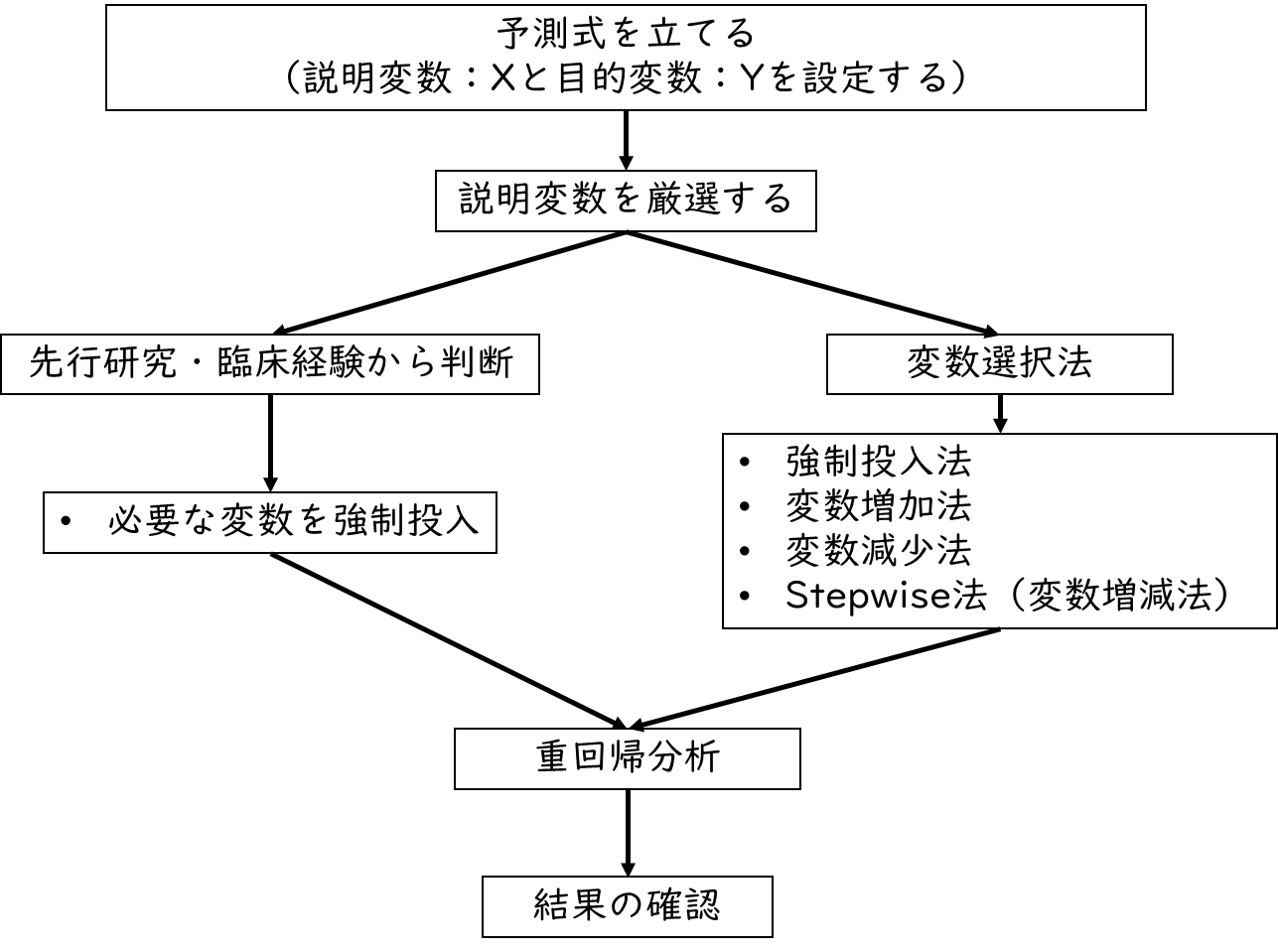
重回帰分析では、まず予測式を検討することから始めます。予測式とは回帰式のことです。説明変数xと目的変数yを設定し、先ほどのy=a+bxの関係性についての仮説を立てます。
yに影響を及ぼしそうなxを検討しよう
仮説を立てたら次に、説明変数xを厳選します。重回帰分析なので、説明変数が複数設定されます。しかし全ての説明変数xを使用して分析する不都合があることもあるので、仮説で設定した説明変数xのうち、どれを使用するか厳選する作業が必要となります。
説明変数の選択方法は、変数選択法と呼ばれる方法で、統計的に変数を選択するとともに、先行研究・臨床経験から判断して必要な変数を強制投入します。下記で詳しく解説します。
変数選択法
説明変数を選択するポイントは下記の2点です。
- 変数選択法を使用する
- 先行研究や臨床経験から必要な説明変数を選ぶ
このポイントは、どちらかではなく、どちらも重要となります。
まずは変数選択法の使用です。変数選択法は下記の4つがあります。
| ➀強制投入法 | すべての説明変数を投入して重回帰式を作る方法 |
| ②変数増加法 | 既存の重回帰式に新たな変数を追加していく方法 |
| ③変数減少法 | 既存の重回帰式から変数を減少させていく方法 |
| ④ステップワイズ法 (変数増減法) | 説明変数を入れたり抜いたりしながら最適なモデルを探す方法 |
変数選択法では、ステップワイズ法(変数増減法)が用いられることがほとんどです。
次のポイントが、先行研究や臨床経験から必要な説明変数を選ぶことです。このポイントが特に重要です。変数選択法だけで説明変数を決定してしまうと、臨床的に意味のある変数が抜けてしまうことがあります。そのためあなたの臨床経験をもとに、目的変数に影響を与えると思われる変数を強制投入するようにしましょう。
重回帰分析の説明変数には限度がある
重回帰分析において、検定に投入可能な説明変数は限られています。重回帰分析では、n数÷10の説明変数が推奨されています。例えばn数が100人いるのであれば、投入できる変数は10個となります。
むやみに説明変数を投入しすぎると、変数同士が関係している可能性が高まります。これを多重共線性と呼びます。また回答が極端にすくない説明変数が存在する可能性も高まります。これらが解析結果に歪みを与える可能性があるので、説明変数を選択することは重要です。
EZRで行う重回帰分析の検定手順
それではEZRを使用して重回帰分析を行う方法について解説します。
今回使用するデモデータ
今回は下記のデモデータ(一部抜粋)を使用します。
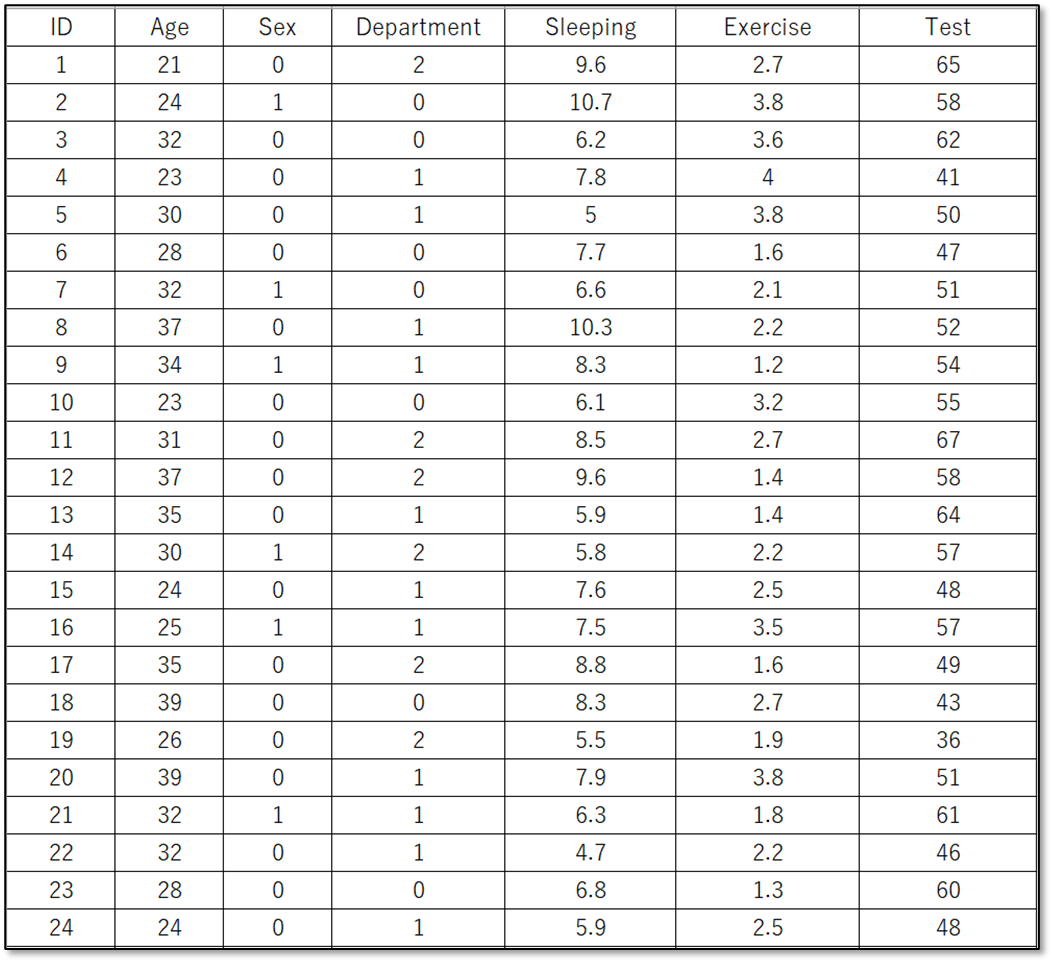
表示しているのは、デモデータの一部です。デモデータは下記からダウンロードできるので使ってみてください。
ランダム関数で作成しているため、今回の結果とズレが出るかもしれませんが、ご了承ください。
こちらのデモデータを読み込んだ後の段階から解説します。データの読み込み方法については【統計解析ソフトにデータを入力】看護研究初めの一歩:EZRにデータセットを入力しよう!を参照してください。
➀まずは予測式を立てる
前述の通り、重回帰分析ではまず予測式を立てることから始めます。
今回は「睡眠時間」と「運動時間」が「テストの点数」に影響を与えるかどうかを考えてみます。

つまり原因である説明変数が「睡眠時間」と「運動時間」、結果である目的変数が「テストの点数」です。
交絡因子の検討
重回帰分析では、仮説を予測する際に説明変数として交絡因子も含めることが重要です。交絡因子とは調査する変数以外で結果に影響を与える変数のことです。この変数を適切に調整しないと、研究結果の解釈に誤りが生じる可能性があります。
交絡因子は下記の3つの条件を含めるものと言われています。
- ➀結果に影響を与える
- ②原因との関連がある
- ③原因と結果の中間因子(原因と結果の間にある)ではない

交絡因子は簡単に言うと、事前の仮説以外にも影響のありそうな因子のことです。今回は交絡因子として「年齢」と「性別」「部署」も説明変数に投入にします

上記を踏まえて今回の予測式を図にすると、説明変数が「睡眠時間」「運動時間」「年齢」「性別」「部署」とし、これらの説明変数が目的変数である「テストの点数」に影響を与えるかどうかを検討します。
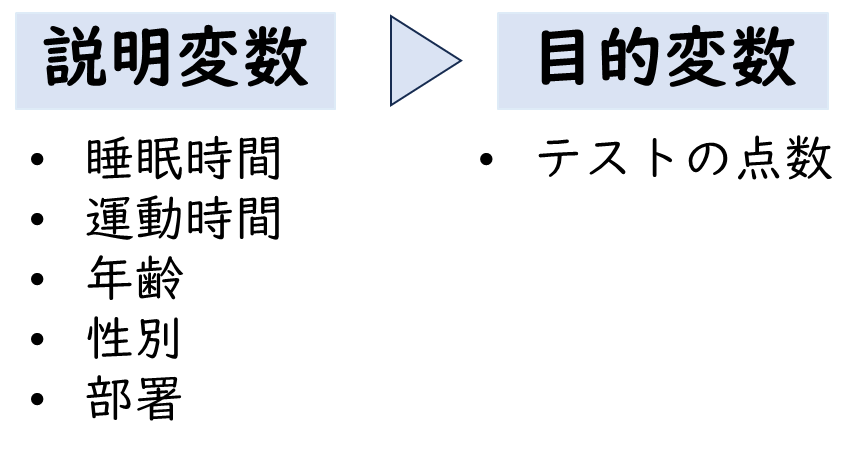
②説明変数を選択する
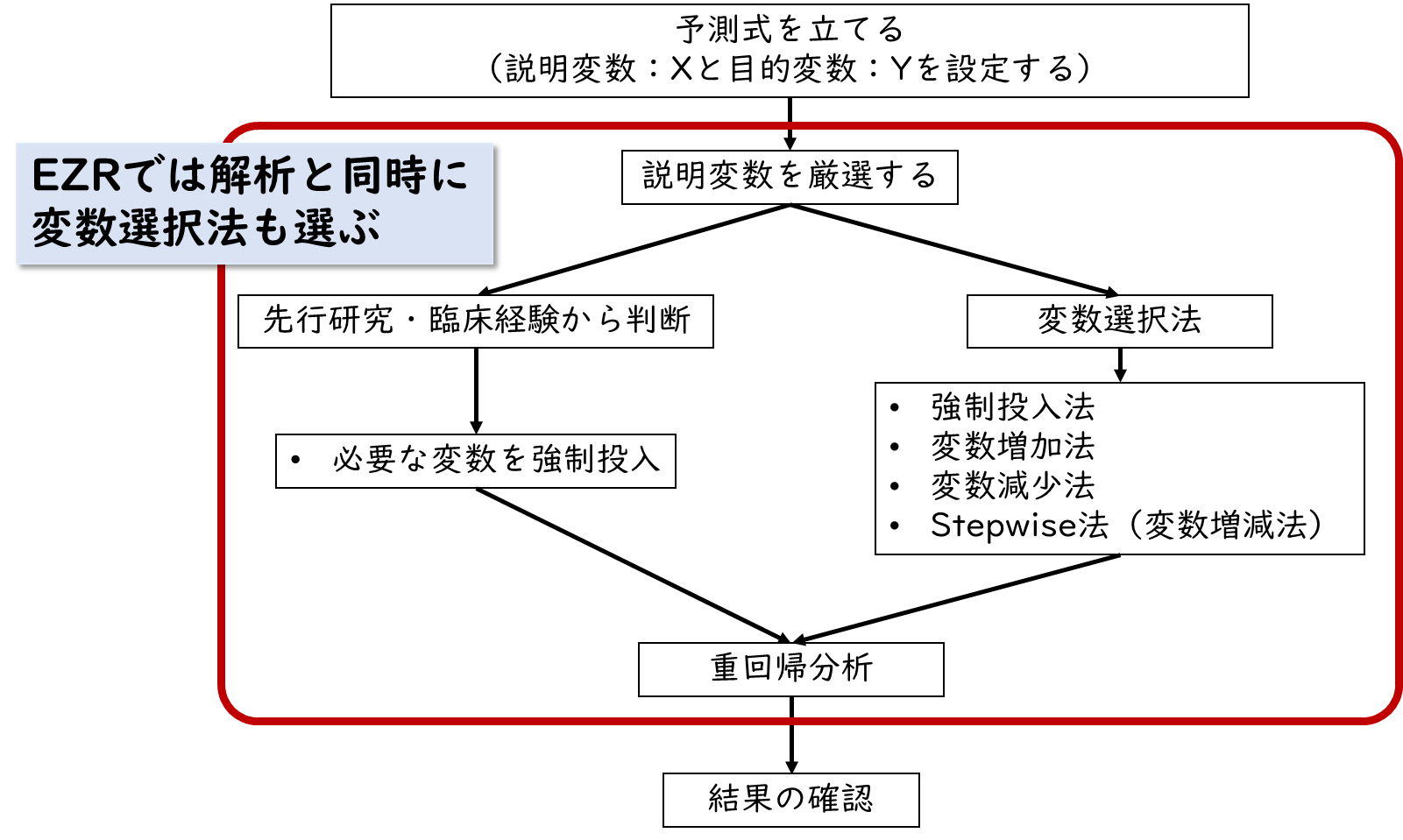
予測式を立てることができたら、設定した説明変数がほんとに適切かを検討します。EZRでは解析と同時に変数選択法も選ぶので、解析する手順の中で、変数選択法についても一緒に解説していきます。
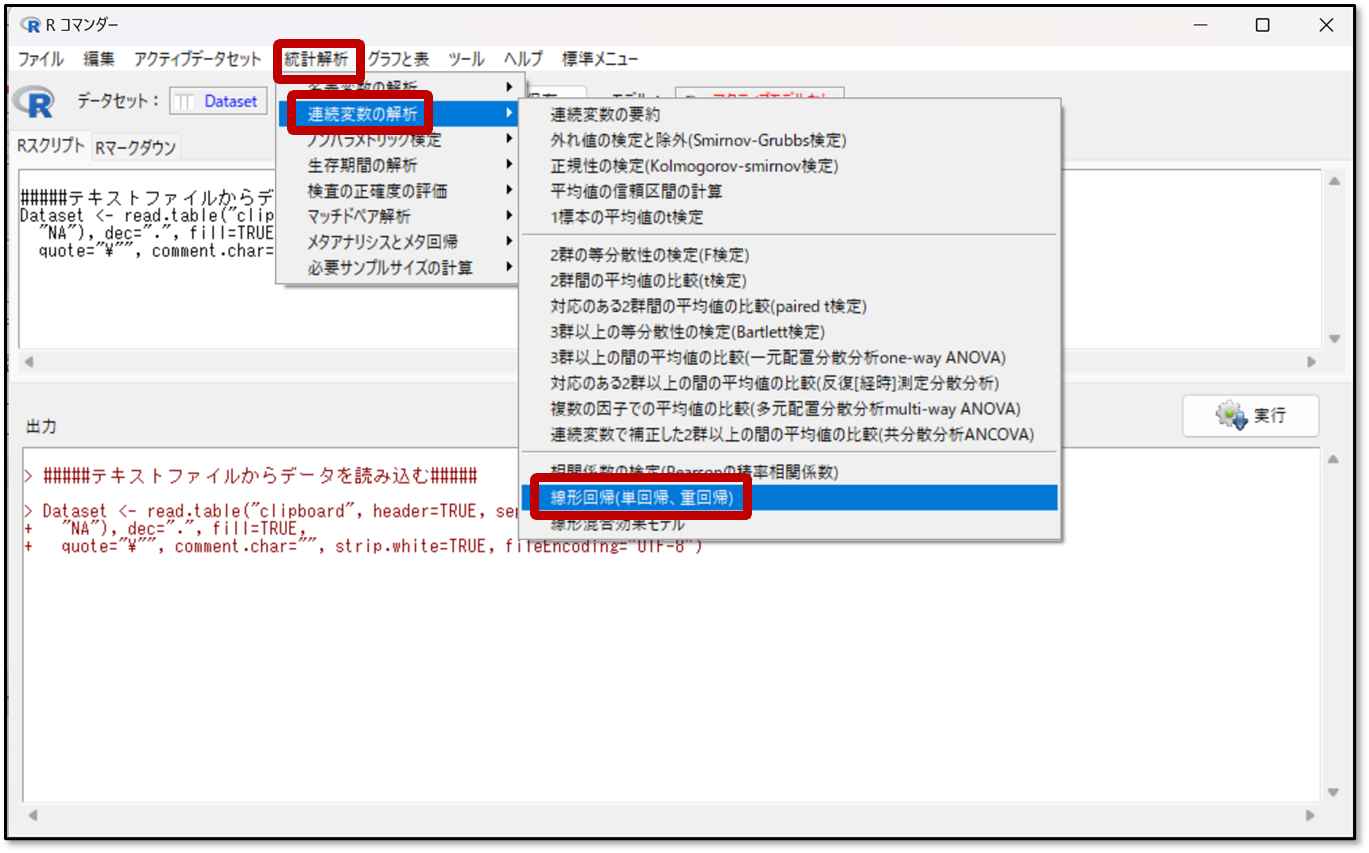
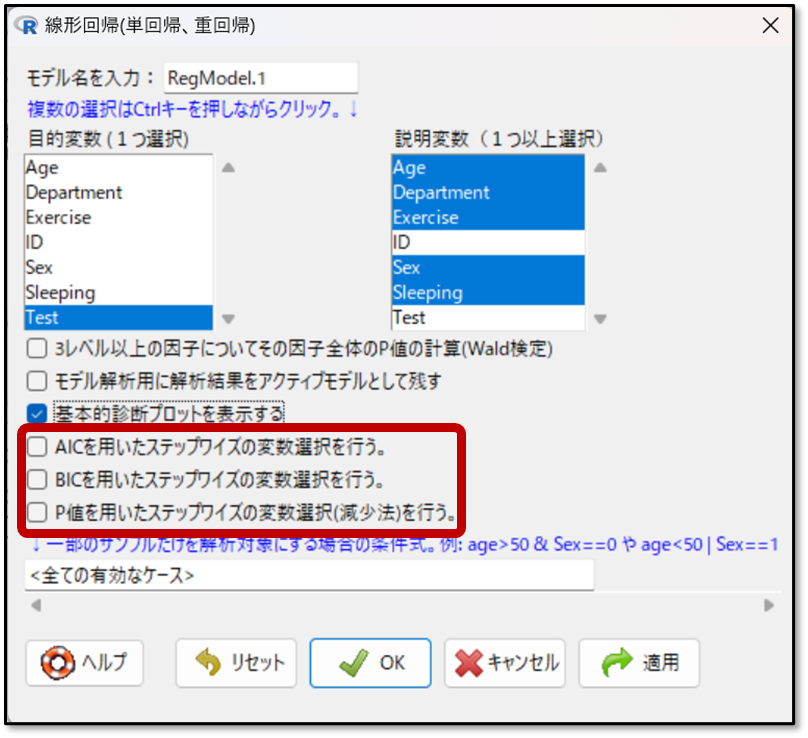
それではEZRで重回帰分析を行う手順を解説します。操作画面より「統計解析」→「連続変数の解析」→「線形回帰(単回帰、重回帰)」の順に選択します。
次に下記の画面で目的変数と説明変数を選択します。今回は目的変数として「Test」を選択し、説明変数は、「Age」「Department」「Exercise」「Sex」「Sleeping」を選択します。
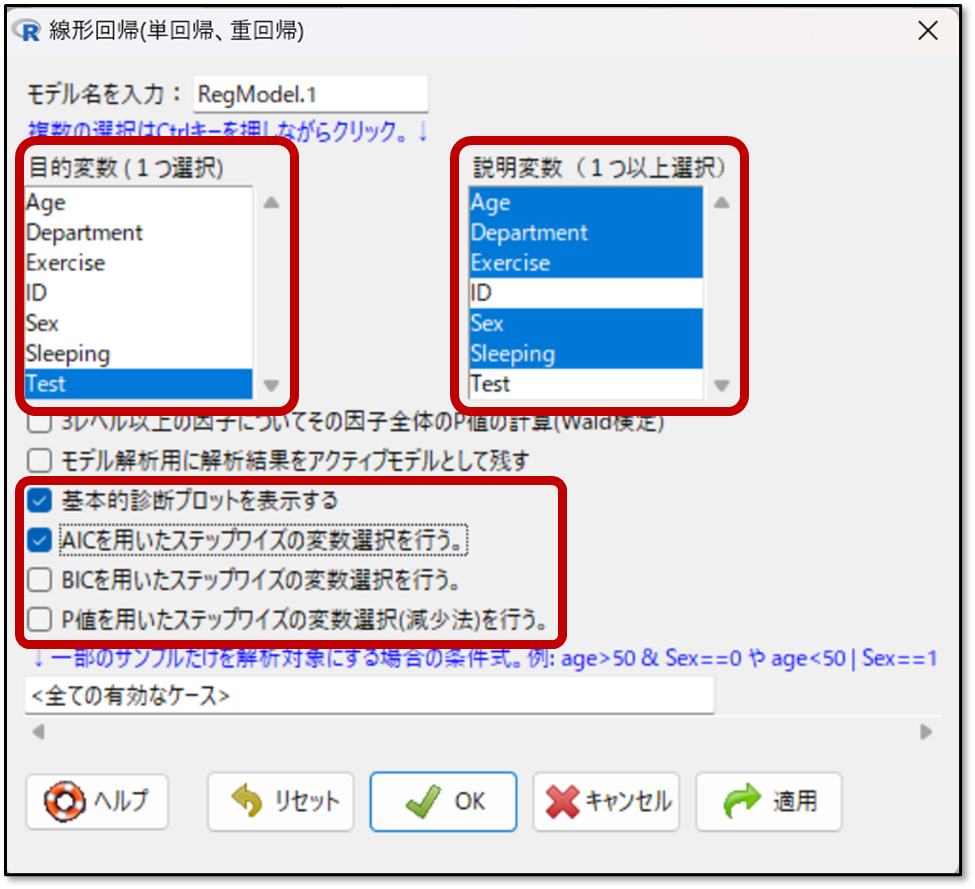
この段階で、変数選択法も選びます。EZRでは、AICもしくはBICを用いたステップワイズの変数選択法と、p値を用いた変数選択法を選ぶことができます。基本はAICもしくはBICを用いたステップワイズの変数選択法選びます。
AIC・BICとは?
AICとは(Akaike’s Information Criteria)の略で、BIC(ベイジアンBayesian Information Criteria)の略です。モデルの最適さを示す指標とだけ覚えておきましょう。
先に解析時の選択ですが、特別な理由がなければAICの使用を推奨します。BICでは選択される変数の数が少なくなる傾向にあります
後程QQプロットを確認する必要があるため、基本的診断プロットにもチェックを入れておこう
あとは、OKを押して解析スタートです。
強制投入はしなくて良いの?
まずはステップワイズ法にて説明変数を絞った後に、自身が臨床的・先行研究的に重要だと思う変数が除かれてしまった場合に、強制投入を行いましょう。
強制投入法は、先ほどのEZRの操作画面で目的変数に影響を与えると思われる説明変数を全て選択し、変数選択法にチェックを入れずに解析を行えば完了です。変数選択法が行われないので自身の考える説明変数で解析することができます。
ステップワイズ法への批判
ステップワイズ法は便利な方法ですが批判的な意見もあるので覚えておきましょう。
ステップワイズ法を使用して変数を選択することについて、「少数の説明変数で予測可能なモデルを作成する場合」には有効な方法であるが、「因果関係を分析することが目的である場合」には適切ではないとの考え方があります。
「因果関係を分析することが目的である場合」は何が目的変数に影響するのかという仮説の設定が重要となります。そのため、統計的に仮説上必要な変数が除去されてしまうのは問題があります。看護研究で多いのは、因果関係を説明することが目的の研究です。
ですが基本を学ぶ上では、ステップワイズ法を選択するのも悪くないと思います。そのため基本的には、前述のようにステップワイズ法と強制投入法を組み合わせて行うことをおすすめします。
因果関係を明らかにする研究では、「事前の仮説で自分が重要だと思う説明変数を最大10個選ぶ方法」を推奨している人もいるよ。
正規分布の確認はしなくて良いの?
重回帰分析では、目的変数や説明変数の正規分布を確認する必要はありません。単回帰分析も重回帰分析も本来はパラメトリック検定、つまり正規分布のデータへの統計手法ですが、一般的には分布を問わず同様の手法で行われています。またノンパラメトリックの手法で重回帰分析の検定ができる統計ソフトがほとんどないとの現状があります。
そのため正規性の確認は必要ありません 。ただし、分析結果の「残差」の正規性については確認する必要があると言われています。これについては後程解説します。
③重回帰分析の結果を確認する
それでは重回帰分析を行った結果を見て行きましょう。
重回帰分析は確認すべき結果が多いから詳しく解説していくね
まずは変数選択の結果を確認
下記が今回の変数選択の結果です。まずはどのような予測式を立てて行った分析なのかを改めて確認しましょう。
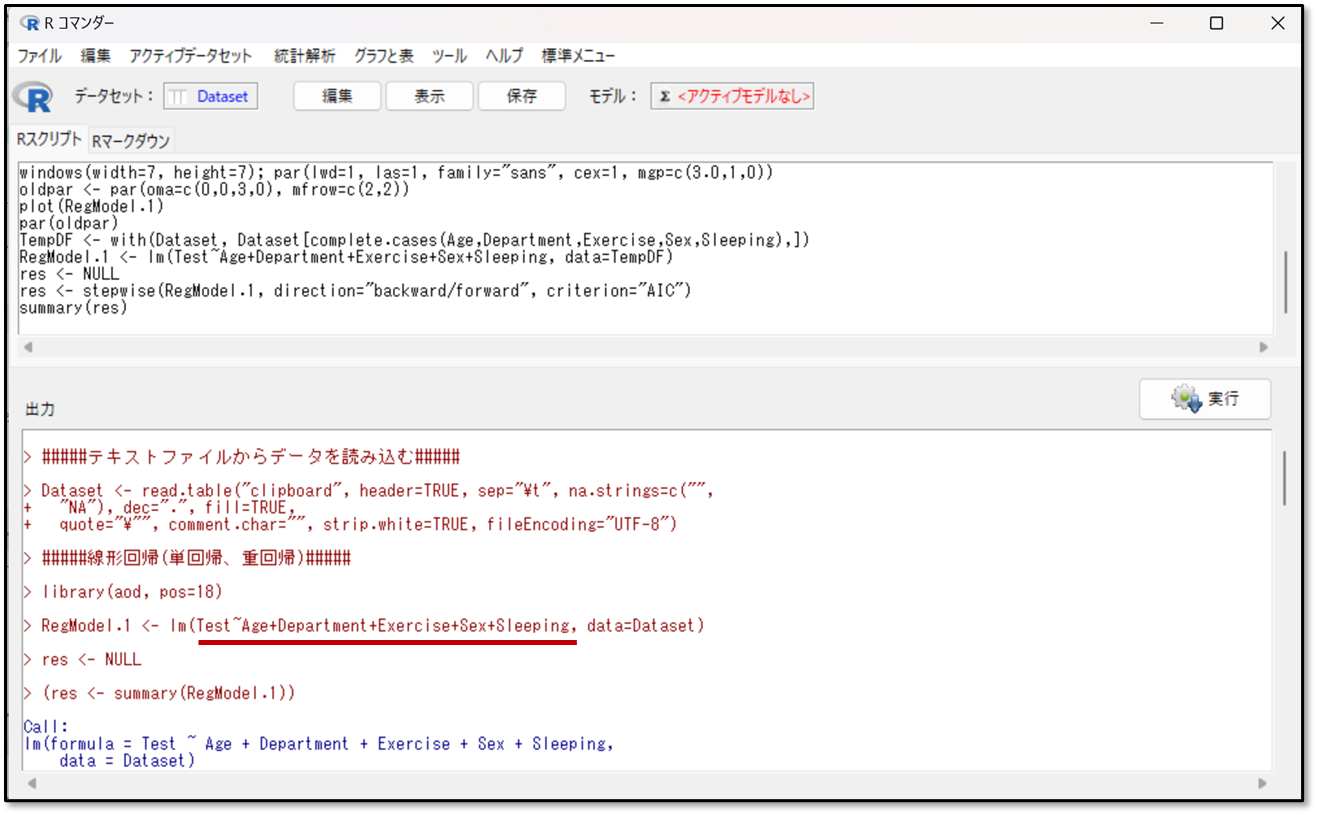
上記の出力画面の赤線の部分が、ステップワイズ法にて説明変数を選択する前の、自身で設定した予測式です。目的変数~波線、説明変数+説明変数+・・・と表示されます。今回の場合だと目的変数のテスト=年齢+部署+運動時間+性別+睡眠時間の予測式を立てて、解析を行ったことが分かります。
次に予測式の説明変数がどのように選択されたか確認します。下記に変数選択後の予測式が出力されています。
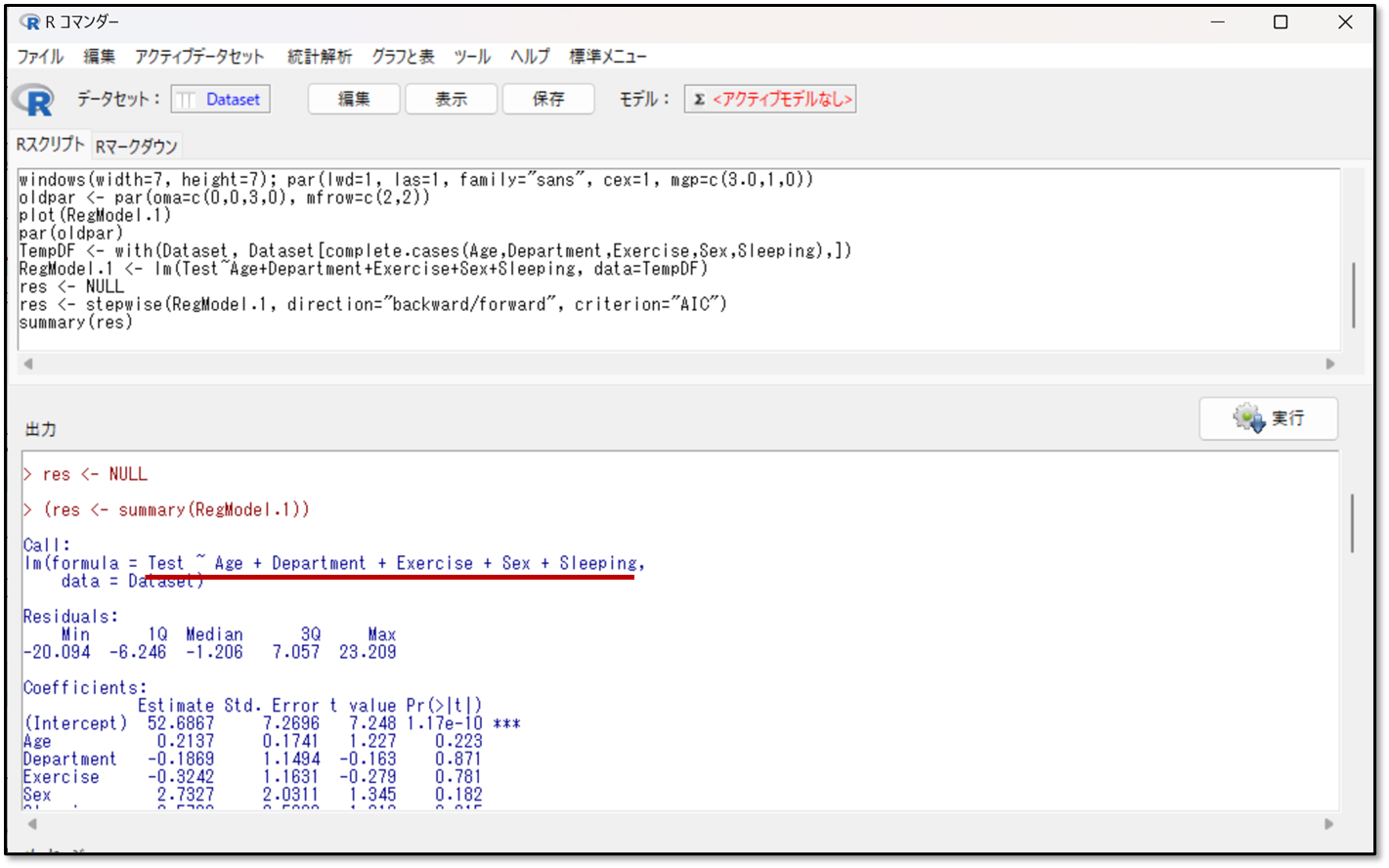
上記の赤線部分が、ステップワイズ法にて選択された説明変数が含まれた予測式です。さきほど同様に、目的変数~説明変数+説明変数+・・・と続きます。つまりY=X+X+・・・という予測式のことです。
今回の変数選択法により導かれた予測式は、最初に設定したものから変更はありません。そのため説明変数は最初に設定したものから削られなかったということです。
もしこの段階で、仮説設定上、重要な変数が削られてしまった場合は、変数選択法にて選ばれた説明変数と、重要だと考えている変数を含めた上で強制投入法を行いましょう。
重回帰分析の結果を確認
重回帰分析の結果は下記について確認します。
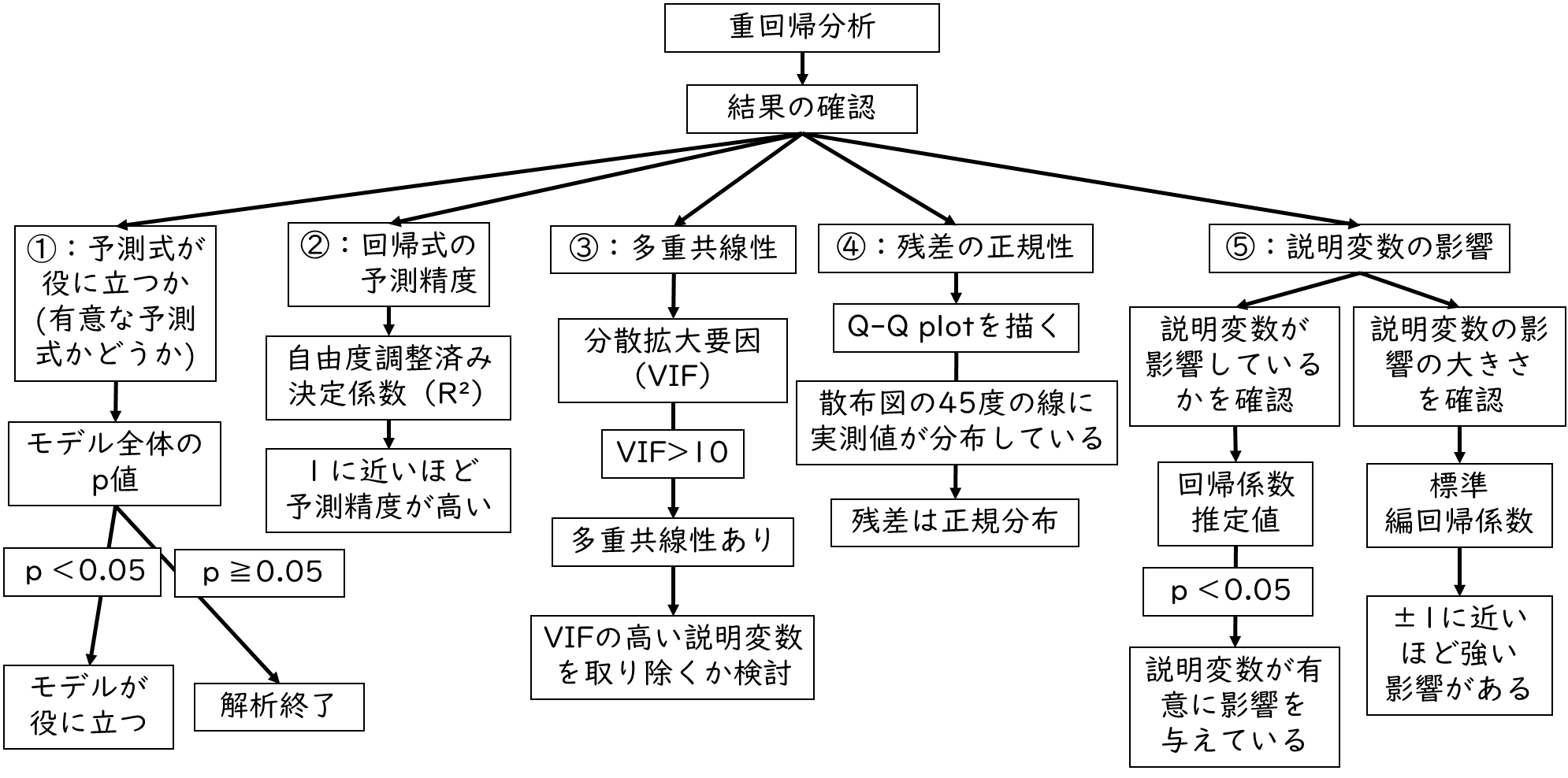
それぞれ詳しく解説するよ
➀予測式が役に立つかどうか(モデル全体のp値)
まずは今回の予測式が役に立つか、つまり有意な予測式かどうかを確認します。そのために出力結果上で、モデル全体のp値を確認します。
重回帰分析では、そもそも今回設定した予測式が役に立つかどうかが重要となります。先ほどの変数選択にて仮説として設定した回帰式が役に立つかどうかを判定します。
ほとんどの統計ソフトで重回帰分析を行うと予測式全体のp値が出力されます。pが0.05未満ならば役に立つ回帰式と判断します。またpが0.05以上ならば役に立たない(予測が当てにならない)回帰式と判断し、この時点で解析終了となります。
下記が今回の解析結果です。
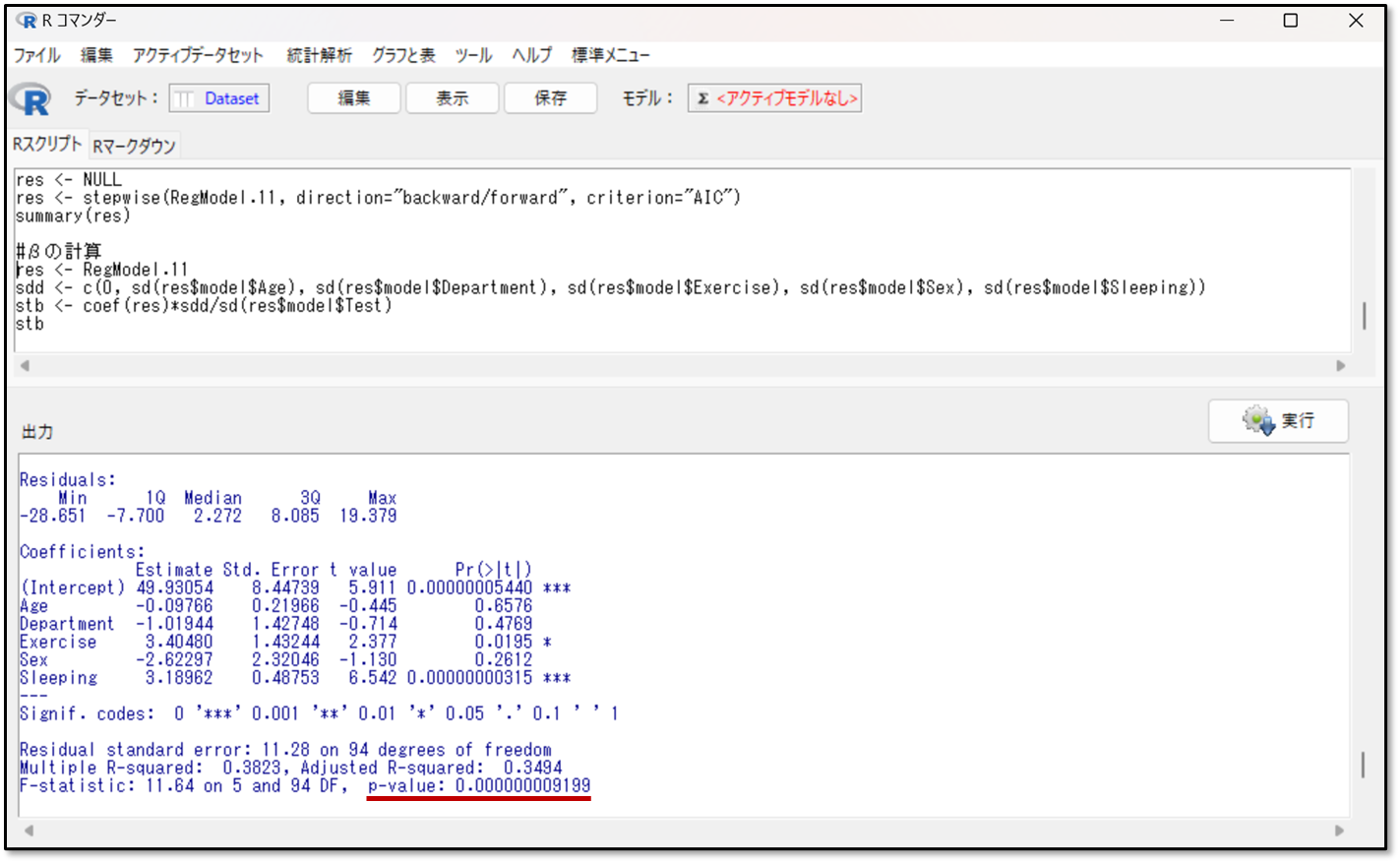
赤線のp-valueがモデル全体のp値です。これが予測式が有意であるかを確認する指標です。今回はp値が0.00000000009199 つまりP<0.05のため、有意な予測式であると判断します。
②回帰式の予測精度(R²)
次に仮説として予測した回帰式の予測精度を判定します。回帰式の予測精度は自由度調整済み決定係数(R²)で確認します。
重回帰分析では、説明変数から目的変数の値を予測するための回帰式を作成し、将来予測をするためにも活用します。そのため算出した回帰式が、どの程度、説明変数から目的変数を予測できるかを確認する必要があります。
その際に確認するのが、自由度調整済み決定係数(R²)です。自由度調整済み決定係数(R²)とは回帰式の予測精度を表す指標、寄与率とも呼ばれます。
R²は0から1の範囲を取ります。R²は1に近づくほど回帰式の予測精度が高いとされています。一般的には、R²が0.5より大きければ予測精度が高い回帰式と判断します。
あくまで目安なので、値が低いから問題というわけではないので注意しましょう
下記が今回の出力結果です。
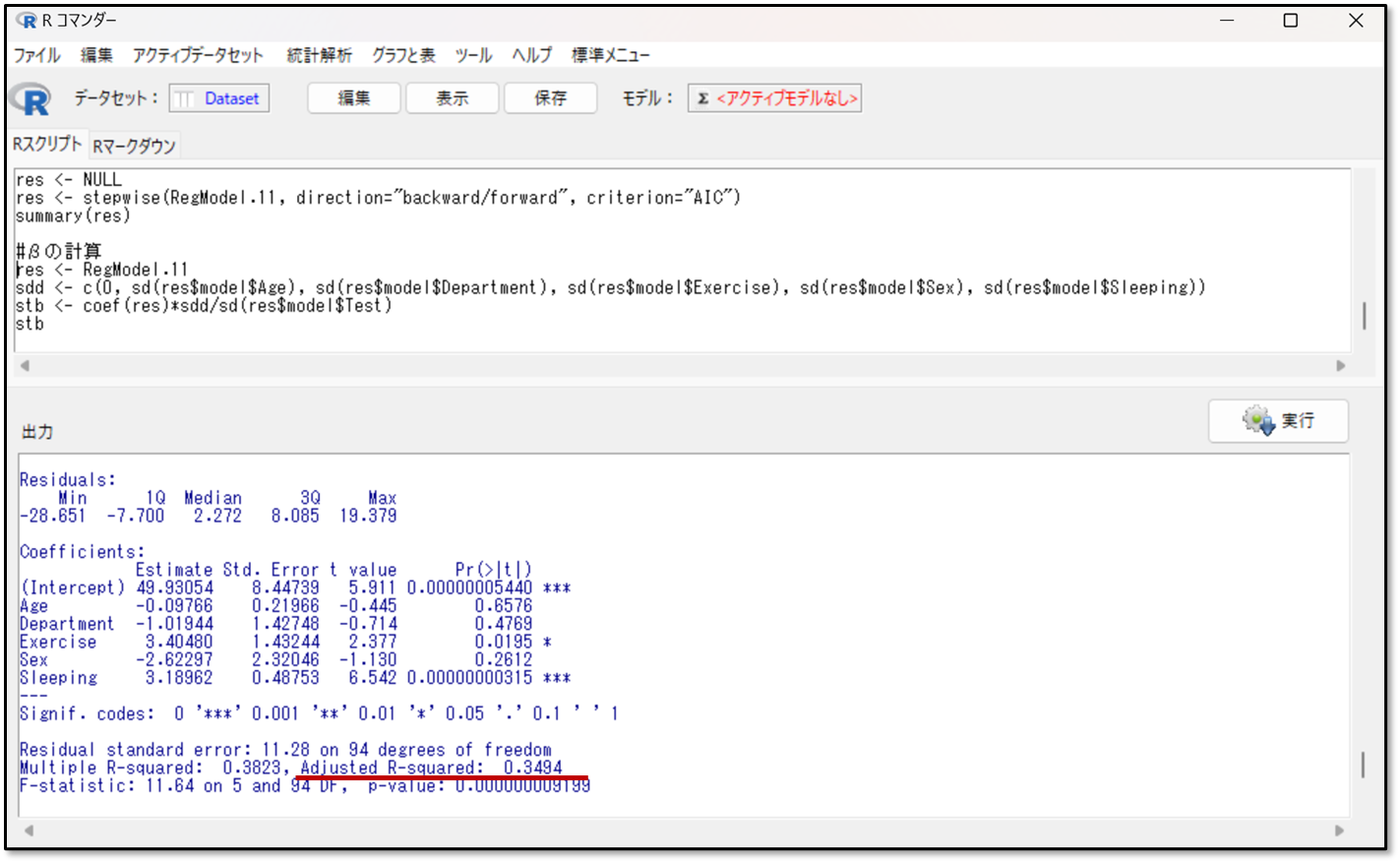
出力結果のAdjusted R-squaredと書いた部分を確認します。今回の結果は、0.3494でした。1に近いほどモデルの妥当性が高い(予測精度が高い)と判断するので、少し低い値です。
③多重共線性(VIF)
多重共線性とは説明変数と説明変数の間の関係の強さのことで、複数の説明変数間に高い相関(強い関係)がある場合に適切な分析結果が出ない状況のことです。
分散拡大要因(VIF)が算出できる場合は、VIFにより多重共線性の有無を確認します。基準はVIFが5以上で多重共線性の可能性ありと判断し、VIFが10以上で多重共線性の可能性がかなり高いと判断します。多重共線性がある場合は、VIFが高い変数を除去して再度分析を行います。
VIFが算出できない場合は、各説明変数間の相関係数を確認して、相関係数が0.9以上であった場合に多重共線性があると判定するよ。この場合は、相関係数が0.9以上の変数を除去して再度分析を実施しよう。
下記が今回の出力結果です。
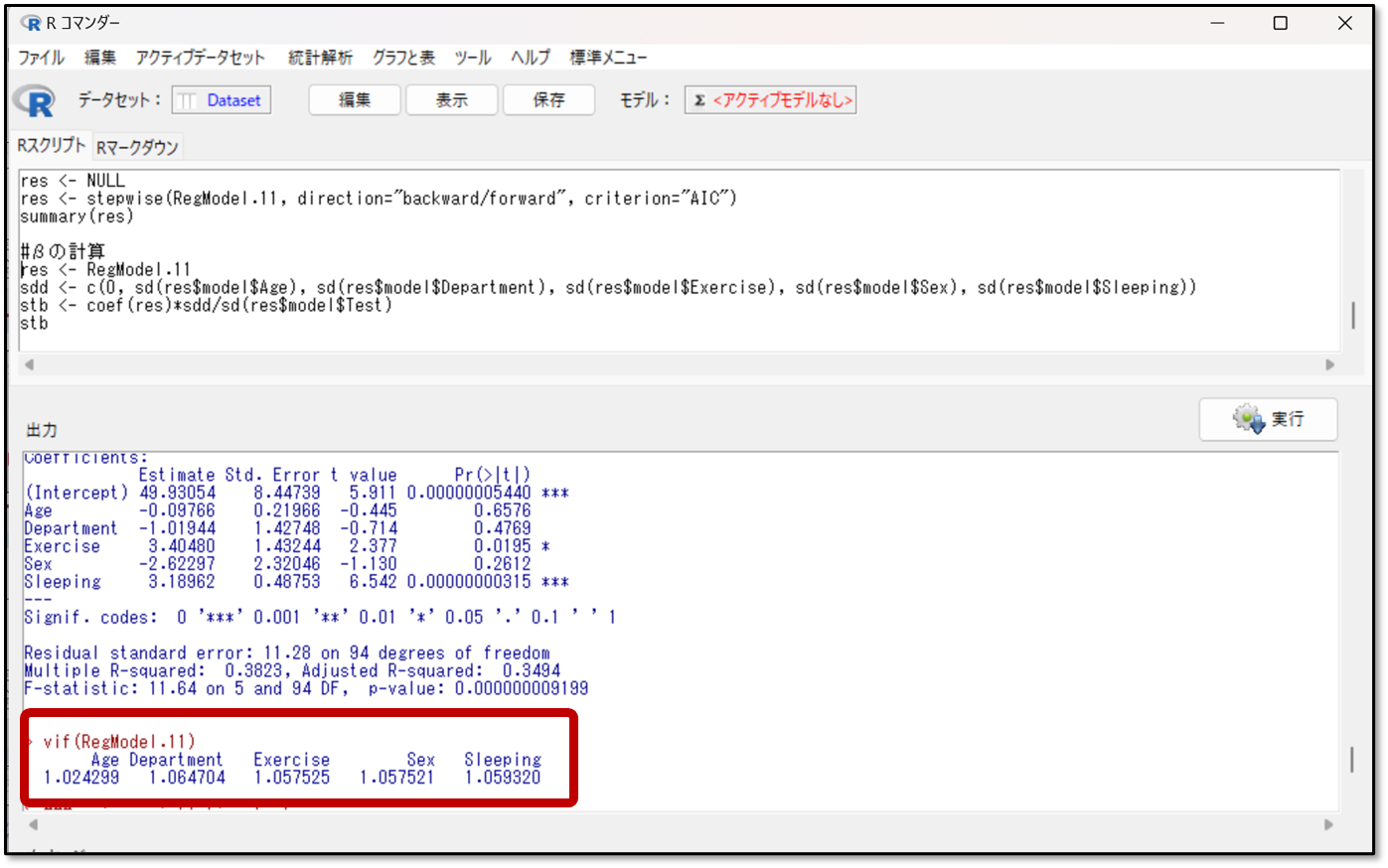
上記のvifと書かれたところを確認します。今回だと、全てが1から1.1の間なので、多重共線性の可能性は低いと判断します。
④残差の正規性(Q-Q plot)
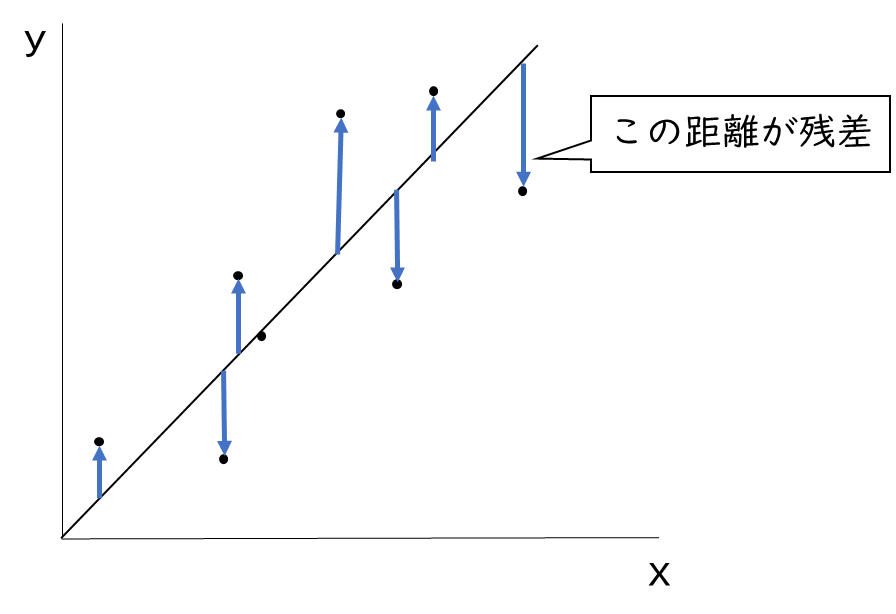
残差とは、実測値と予測値の差のことです。
実測値と予測値の差とは、下記の図のように回帰直線(真ん中の線)から垂直に伸ばした各データ値までの距離のことです。
つまり、観察された値と仮説として予測した値との差のことです。回帰分析では残差が正規分布に従っていることが前提とされています。
残差の正規性は、解析結果のQ-Q plotから確認します。Q-Q plotでは今回の分析での散布図を確認することができます。
出力されたQ-Q plotの回帰直線(真ん中の線)の周りの点である実測値が、ランダムに散らばっていたら残差が正規分布に従っていると判断します。
回帰直線(真ん中の線)から明らかに遠くに位置するような実測値がある場合は、外れ値と呼ばれる入力間違いなどで大きく外れた値の可能性もあるためデータを再度確認してみましょう
ちなみに外れ値が正しい測定結果だった場合は、何か重要な意味がある可能性もあるため注意して分析しよう
それでは今回の結果を確認します。下記が今回の分析で出力されたQ-Q plotです。解析前の操作画面で「基本的診断プロットを表示する」にチェックを入れておくと、下記の画像が出力されます。
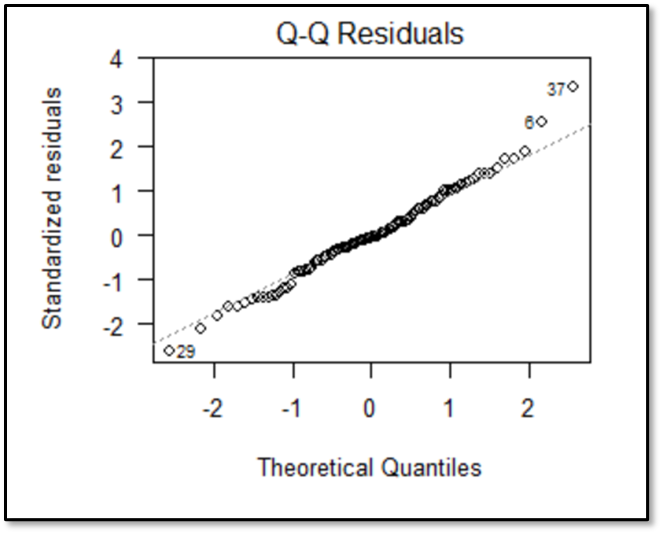
今回の結果を見ると、観測された実測値は回帰直線(真ん中の線)の周りに散らばっているので、残差は正規分布に従っていると判断します。また大きく外れた値(外れ値)が無いことも分かります。
⑤説明変数の影響(有意に影響があるか:説明変数のp値)
説明変数が目的変数に有意に影響があるかどうかは説明変数のp値(回帰係数推定値)を確認します。
回帰係数推定値がP<0.05の場合、「説明変数は目的変数に有意に影響がある」と判断できます。ただしP≧0.05であっても、全く影響がないわけではないので注意しましょう。
それでは今回の結果を見てみます。
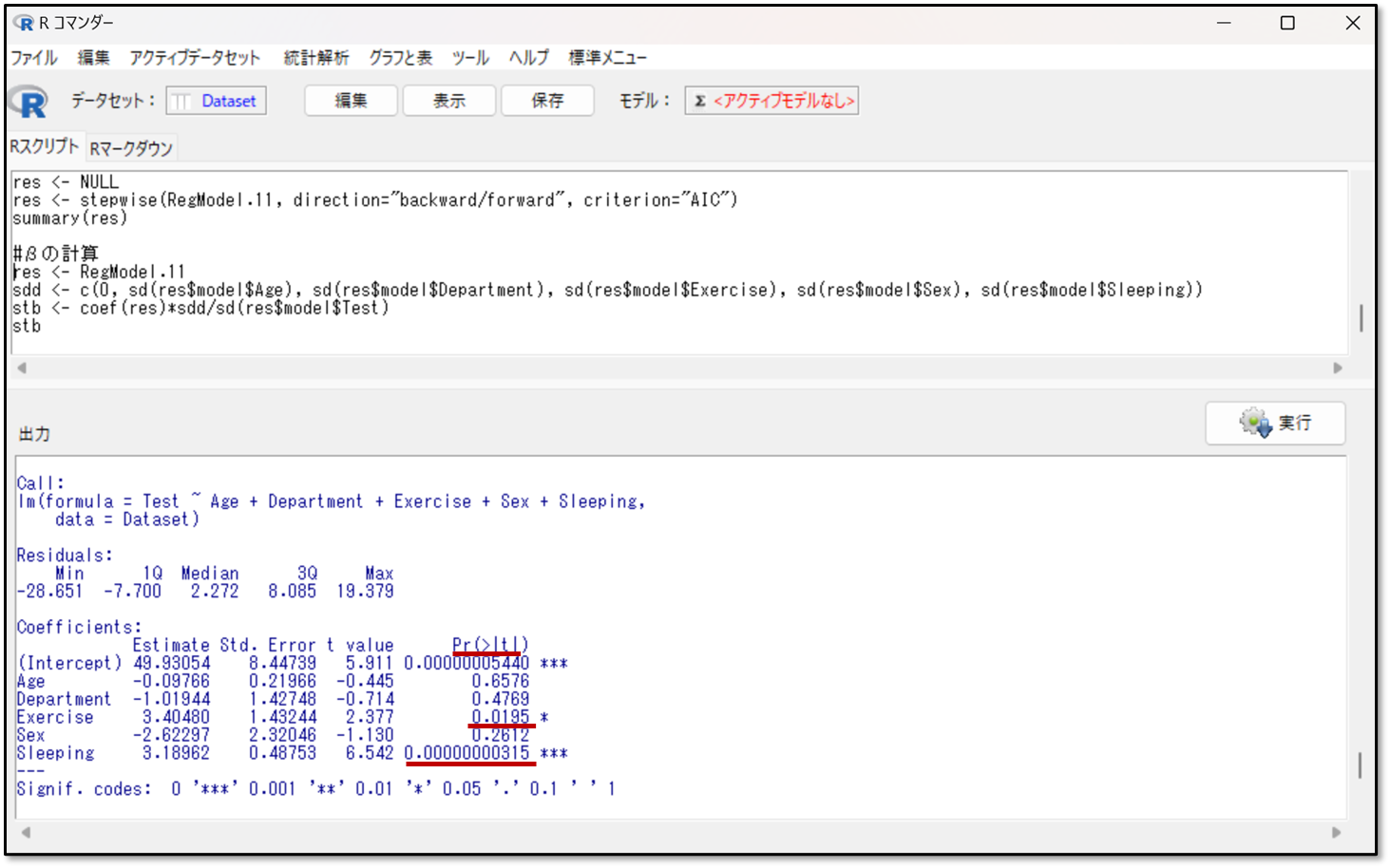
各説明変数のp値を確認します。今回の結果だとExercise(運動時間)がp=0.0195 、Sleeping(睡眠時間)がP=0.00000000315と出力されており、これらがp<0.05であり目的変数に有意に影響を与えている説明変数であると判断します。
⑤説明変数の影響(影響の大きさ:編回帰係数)
最後が説明変数の影響の大きさです。説明変数の影響の大きさは編回帰係数で確認します。編回帰係数を確認することで、各説明変数が目的変数に対してどの程度の影響を与えているかを判断することができます。
ただし、編回帰係数のままだと説明変数の単位の影響を受けるため、単位の異なる説明変数同士の影響の大きさは比べることができません。そのため標準編回帰係数(β)を確認します。
標準編回帰係数(β)とは、編回帰係数と同様に各説明変数の影響の大きさを比較できる値です。編回帰係数との違いは、それぞれの説明変数の単位を標準化して、相対的に目的変数への影響の度合いを比較できるようにしているところです。
基本的には標準編回帰係数(β)だけ確認すればOKだよ
標準編回帰係数(β)は、-1~+1の値を取り、±1に近いほど強い影響があります。下記の表が一般的に判定の目安として使用される指標です。標準編回帰係数は、相関係数と同様に+も-もあるので、絶対値で表現されています。
あくまで目安のだから、自分の臨床経験なども踏まえながら結果を解釈しよう!

下記がEZRで出力した結果です。
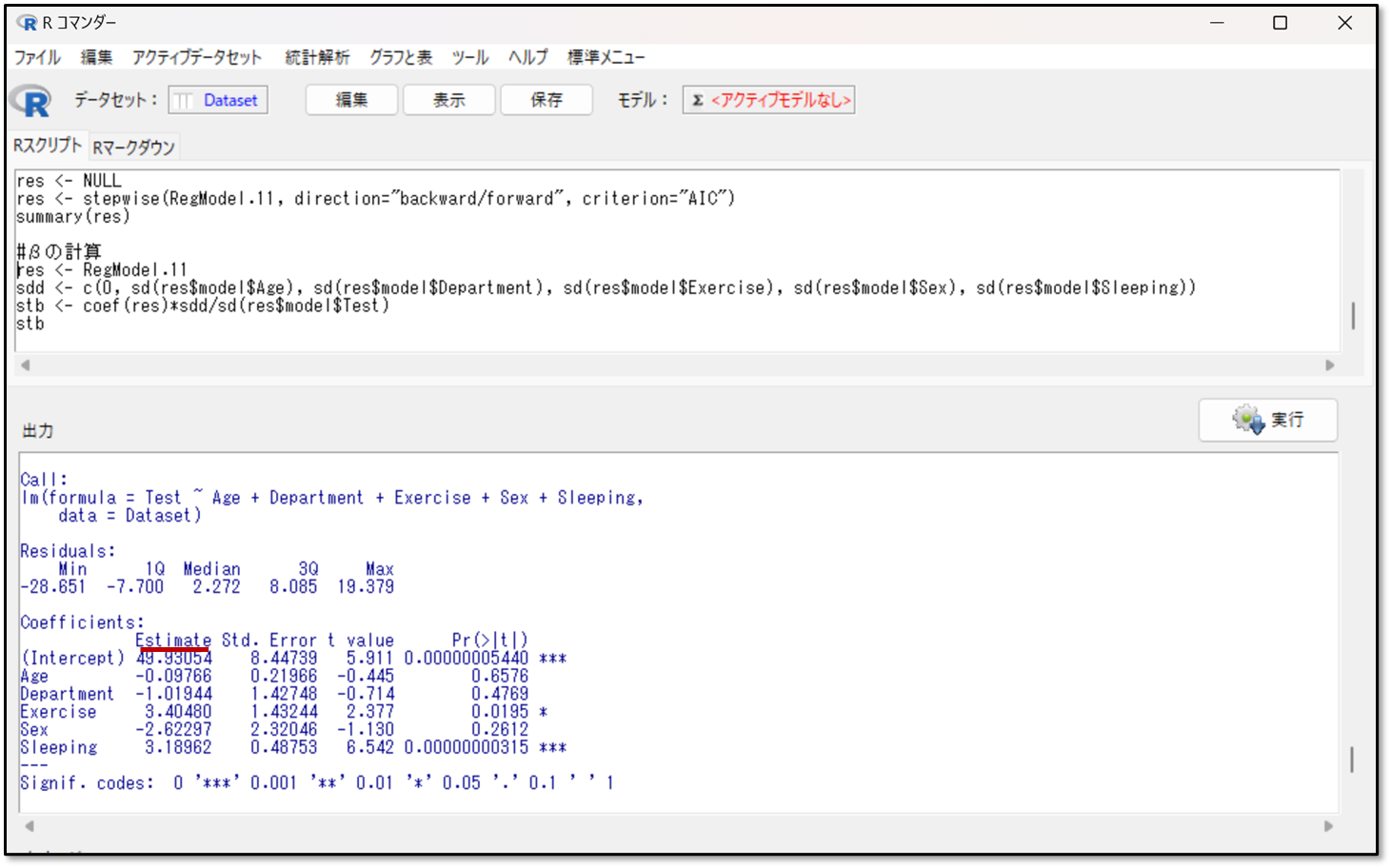
EZRでは標準編回帰係数は出力させれず、編回帰係数のみが出力されます。上の図のEstimate(エスティメイト)と書かれているところが編回帰係数です。
編回帰係数は前述の通り、単位が異なる説明変数を比較することができないため、少し手間が掛かりますが標準編回帰係数(β)を算出しましょう。
標準編回帰係数βの算出方法
まずはEZRの操作画面のRスクリプトに下記のコードを入力します。下記のコードの赤字の部分を自身の分析内容に変更してください。説明変数については、適宜増減してください。
Rスクリプトとは、EZRの画面の赤枠の部分です。
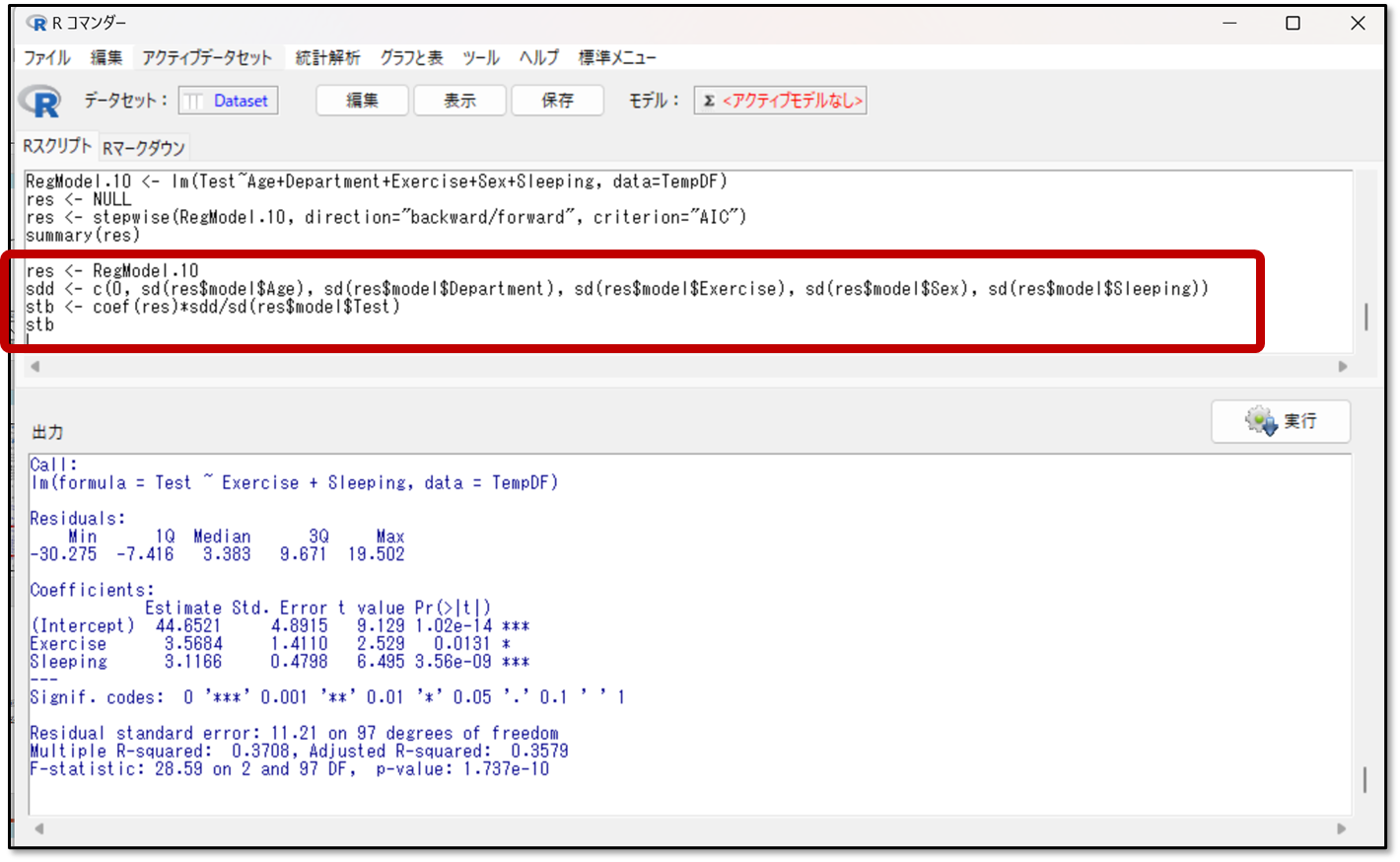
モデル名とは、解析条件を入力した操作画面に記載のモデル名です。
Rスクリプトに先ほどのコードを入力したら、コードを選択して実行をクリックします。
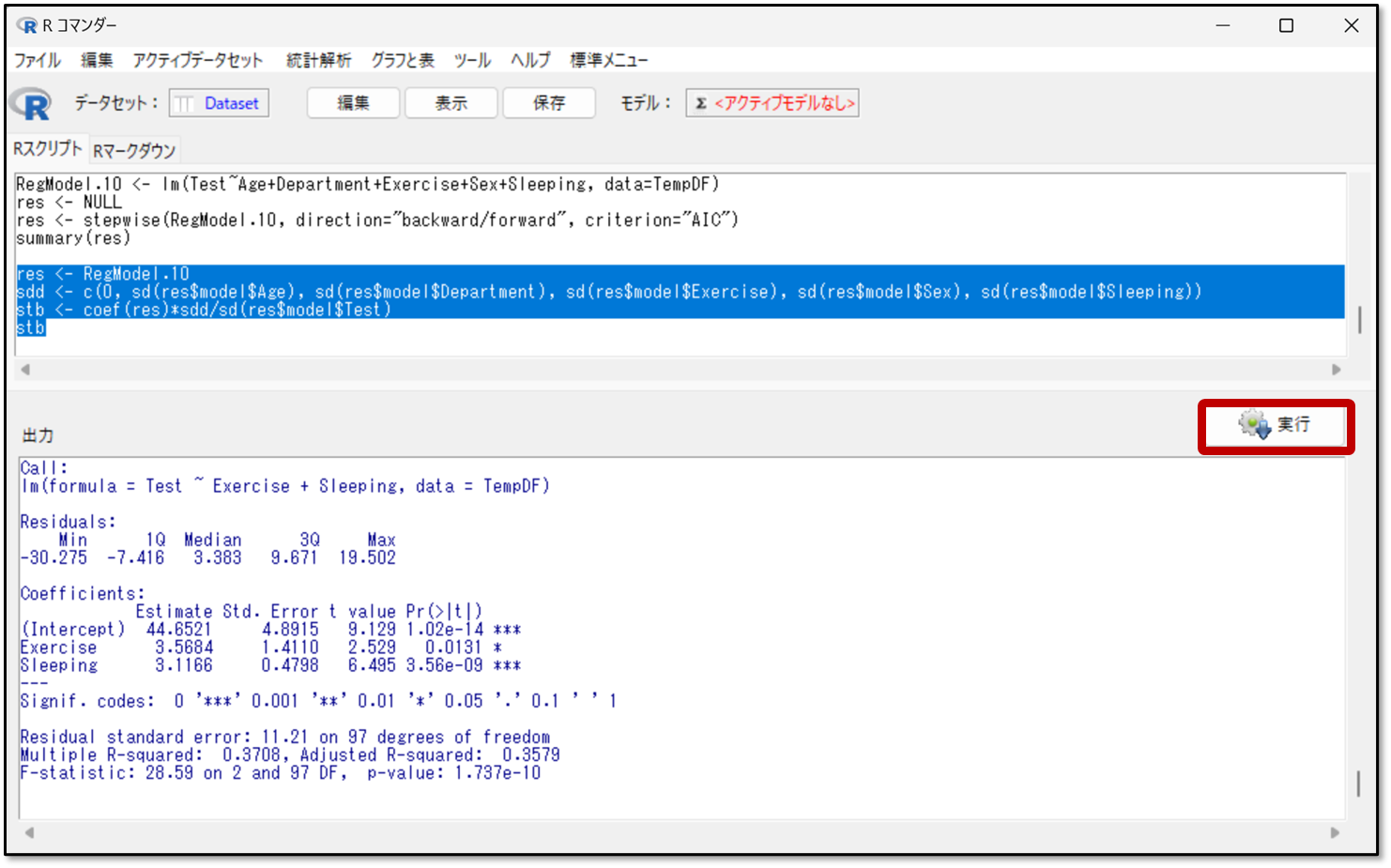
下記が今回の標準編回帰係数の出力結果です。
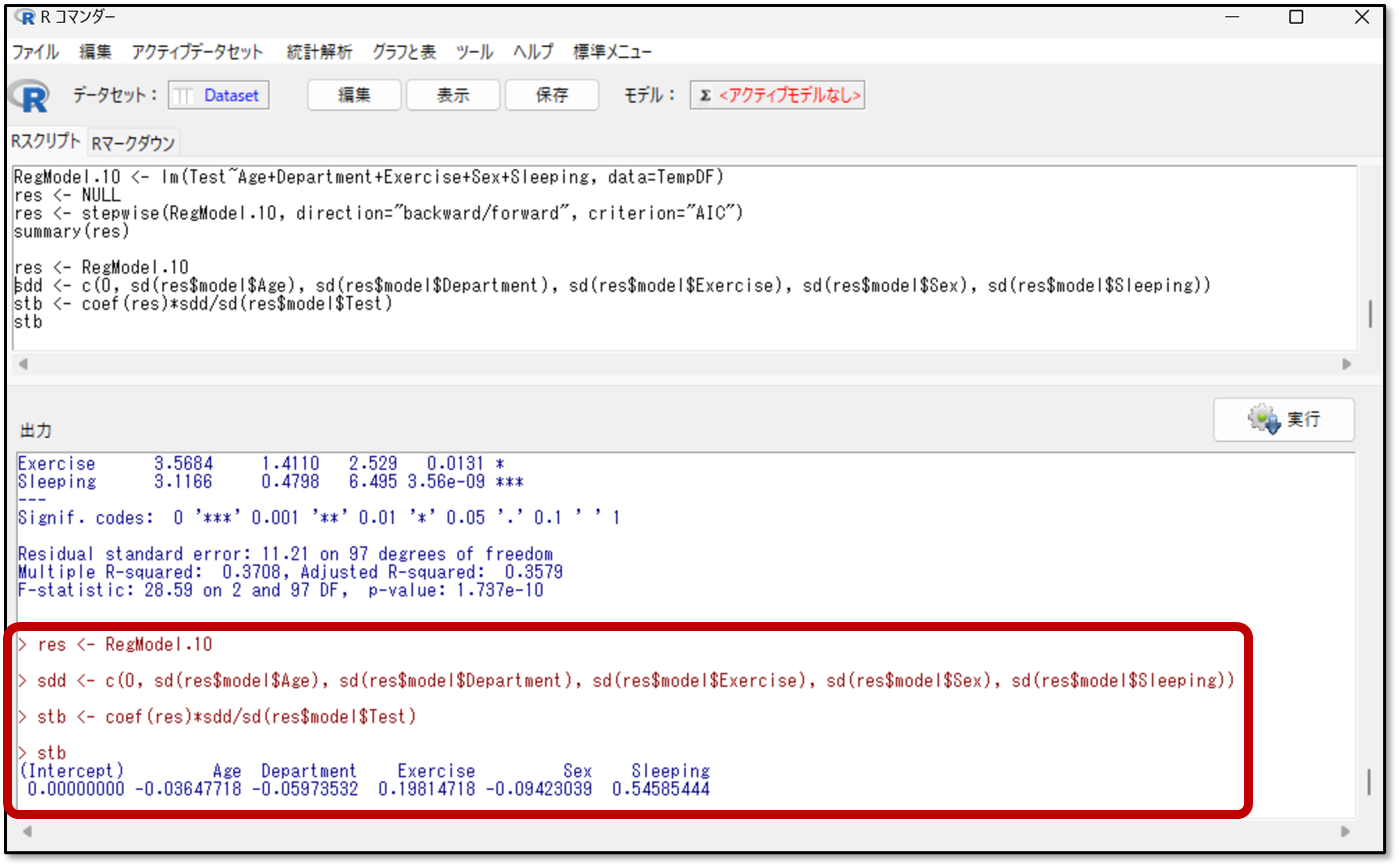
今回の結果だと、例えばSleeping(睡眠時間)の標準編回帰係数は0.54585444で、かなり強い影響があることが分かります。
まとめ
重回帰分析は、目的変数に影響を与える複数の要因を同時に考慮するための便利なツールです。この分析を使えば、さまざまな説明変数がどのように目的変数に影響するかを理解しやすくなります。そして、その理解をもとに、より効果的な看護介入を立案できるようになります。この記事が、重回帰分析の基本を理解し、実践するための助けとなることを願っています。
この記事を通じて基本的な理解を深め、実際のデータ解析に活かしていただければ幸いです!
今回は重回帰分析を実際に行う方法を解説しました。重回帰分析の概要について詳しく知りたい方は【重回帰分析:概要編】看護研究の疑問を解決「因果関係を調査しよう」を参照してください。


コメント